Analyser de la donnée
Analyse simple
Dans les deux précédents chapitres, nous avons montré comment nettoyer de la donnée Open Data puis comment en réaliser une analyse visuelle, par le biais de rapports ou de dataviz. Pour l’instant, ces rapports étaient simplement basés sur les données brutes ou en tout cas sans traitement sophistiqué. Bref, l’analyse était laissée à l’appréciation de l’utilisateur du rapport ou de la dataviz, ce qui est largement suffisant dans beaucoup de cas tant la donnée est simple.
Dans le présent chapitre, nous montrerons comment traiter des données dont la lecture graphique n’est pas aisée, soit parce que son caractère trop brut rend complexe sa compréhension, soit parce que le volume de données rend nécessaire une phase de traitement mathématique ou statistique, voire une phase de filtrage des valeurs.
Avant de rentrer dans des outils lourds de traitement statistique/Business Intelligence/Big Data, il convient toutefois de rappeler que presque toutes les analyses peuvent être réalisées avec l’outil le plus utilisé au monde pour l’analyse de données, à savoir le tableur. La versatilité de l’outil et son abord très simple même pour des non-spécialistes ont fait du tableur l’outil numéro un pour le traitement analytique de la donnée, qu’elle soit ouverte ou pas. Le premier exemple dans ce chapitre se fera donc sur Excel.
1. Récupération des données
Jusqu’à ce point du livre, les exemples ont été uniquement extraits de l’Open Data française. Du point de vue du citoyen, la ville, le département, la région et l’État sont les sources principales d’information sur ses besoins immédiats. Toutefois, il est également enrichissant d’étudier les sources étrangères et ce, pour deux raisons. Non seulement cela donne des idées sur des sources qui ne sont pas disponibles en France et qui auraient de la valeur d’usage. Mais en plus, cela permet de voir comment les sources sont agencées dans les autres pays. Force est de constater à l’analyse de l’Open Data en Angleterre et aux États-Unis...
Gérer des données volumineuses
1. Définition du volume
Dans la section ci-dessus du présent chapitre, la quantité de données était plus importante que dans les précédents exemples, mais restait raisonnable, à savoir la moitié du maximum d’un million de lignes qu’Excel peut supporter. En fonction de l’ordinateur utilisé, le chargement du fichier (environ 140 mégaoctets au final) pouvait prendre un peu de temps, mais les temps de manipulation restaient raisonnables.
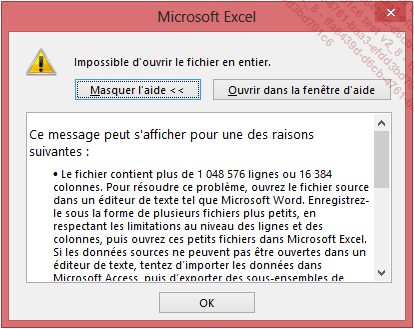
Que faire si les données dépassent le million de lignes ? Excel n’est pas en mesure de dépasser cette limite lorsque les données sont chargées directement dans le tableur, comme le message ci-dessous l’explique :
Pourtant, il est possible de manipuler des données bien plus volumineuses dans Excel, à condition d’utiliser une technologie adaptée. Une de ces technologies est OLAP.
2. Un mot sur OLAP
L’analyse de données est une activité qui a tendance à utiliser de plus en plus de ressources. Au fur et à mesure que les machines devenaient plus puissantes, les analystes ont développé des modèles de plus en plus sophistiqués. Sur leur lancée, les modèles n’ont cessé de se complexifier, mais les machines - à un moment donné - n’ont plus suivi. Après que toutes les solutions simples ont été épuisées (réécrire certains algorithmes pour contourner des limites logicielles là où c’était possible, optimiser les logiciels, dédier des machines, etc.), il a fallu réaliser des modifications plus radicales dans les processus d’analyse de données pour obtenir les performances nécessaires.
L’approche la plus répandue est celle des cubes de données dits « OLAP », et de ce qui est traditionnellement nommé la « BI », pour Business Intelligence. Cette approche a consisté à modifier le compromis entre l’utilisation de l’espace mémoire et la rapidité de mise à disposition de la donnée, en sacrifiant la première au profit de la seconde. De manière pratique, l’idée des cubes est de réaliser...
Rapports sur de la donnée issue de cubes
1. Présentation de l’exemple
Les cubes OLAP ne servent pas qu’à l’analyse proprement dite, mais plus globalement de support de requêtes accéléré à n’importe quel client. Du coup, il est également possible de créer des rapports directement sur les données de Power Pivot, et ce sans effet notable du volume sur la performance une fois le cube préparé. Dans cette section, c’est logiquement l’outil Power BI de Microsoft qui sera utilisé pour créer un rapport sur les données des balances comptables analysées ci-dessus.
Nous parlons bien du produit Power BI intégré à Excel sous la forme des modules Power View et Power Map, et non du produit indépendant nommé Power BI Desktop que nous avons montré dans le chapitre précédent (bien que celui-ci ait récupéré des morceaux d’Excel, comme Power Query).
Comme promis au chapitre précédent, l’exemple utilisera Power BI pour créer une carte des balances comptables. Nous resterons sur les subventions créditées par l’État au budget des communes. Par contre, la source initiale ne fournissant pas la géolocalisation des communes, nous allons lier une seconde source de données pour récupérer ces informations.
2. Intégration des données géographiques
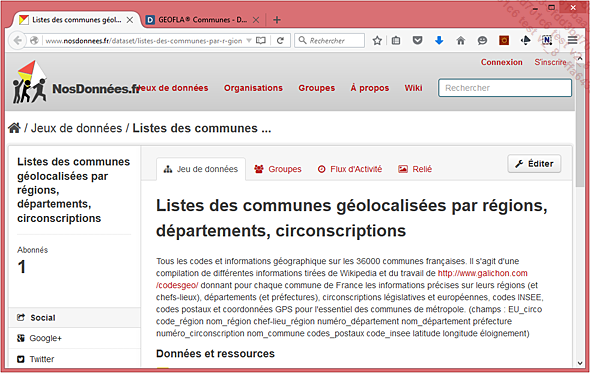
Une recherche de la géolocalisation des communes sur le site de l’INSEE aboutit à la page http://www.nosdonnees.fr/dataset/listes-des-communes-par-r-gions-d-partements-circonscriptions, qui fournit un fichier CSV (compressé lors du téléchargement) avec, pour chaque commune de France, les données des niveaux géographiques supérieurs (région, département, etc.), les codes postaux ainsi que les coordonnées GPS.
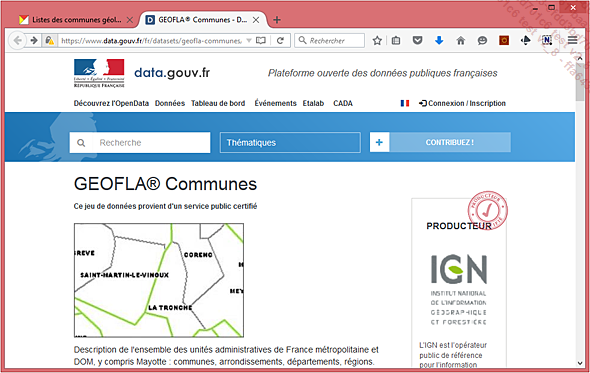
À titre de remarque, si le besoin est de définir des zones en deux dimensions correspondant à la forme des communes, l’IGN met lui aussi en ligne des informations sur les communes, mais au format SHP (shape est la traduction de forme en anglais) comprenant la définition graphique du contour des communes, à l’adresse https://www.data.gouv.fr/fr/datasets/geofla-communes/ :
Le fichier...
Analyse statistique de la donnée
1. Une approche plus mathématique
Après de nombreux exemples où les données ont été analysées par une approche empirique où la représentation était directement en lien avec la donnée, la section qui suit va continuer l’analyse de données en lui faisant prendre un tour bien plus abstrait, par une approche mathématique ou plus précisément statistique.
Même sans connaissance experte de la statistique, des outils spécialisés peuvent donner de nombreuses informations particulièrement intéressantes sur de la donnée. L’outil mathématique peut faire peur à certains, mais nous faisons tous de la statistique sans le savoir quand nous parlons de moyenne, un concept facilement compréhensible, même sans enseignement mathématique préalable.
Le but de l’exemple ci-dessous n’est pas de donner un vernis statistique à l’approche d’analyse de données ouvertes, mais de montrer comment, avec le bon outil et quelques connaissances de base, il est facile de déduire des informations importantes depuis de la donnée brute, et ce sans avoir réalisé le moindre calcul à aucun moment : le logiciel s’occupera de tout pour nous.
2. Choix de la source de données
En ces temps de prise de conscience du réchauffement de la planète, un exemple sur la pollution des véhicules semble de mise. Mettons-nous dans la peau d’une personne qui aime les voitures puissantes, mais rechigne à émettre trop de dioxyde de carbone, pour des raisons morales. Y a-t-il vraiment un lien fort entre la puissance et le taux de CO2 émis, ou serait-il possible dans le cas contraire de trouver la perle rare qui ait un comportement sport tout en restant raisonnable du point de vue des émissions ?
Pour répondre à cette question, il nous faut bien sûr des données, et comme il est hors de question pour un particulier de débourser le moindre centime pour répondre à une telle question, nous nous tournons vers la donnée ouverte. Il se trouve qu’Etalab, en coopération avec l’ADEME, publie des données ouvertes sur la consommation et les émissions...
Aller plus loin
Si toutes les méthodes citées ci-dessus n’ont pas suffi aux besoins d’une donnée ouverte particulièrement volumineuse ou récalcitrante à l’analyse, seules les solutions de Business Intelligence "lourdes" et propriétaires permettront d’aller plus loin encore.
1. Outils de BI lourde
Nous avons rapidement décrit la BI lors de l’introduction à Power Pivot, en précisant que ce qui se faisait dans ce module d’Excel était une version allégée de la BI, tout le contenu devant rester local au classeur Excel. Le non-respect du dogme du Single Version Of the Truth a été fortement reproché à Power Pivot par les zélateurs des approches par cubes OLAP centralisés, et ces approches se basent traditionnellement sur des bases de données tabulaires comme SQL Server ou Oracle.
SAP, SAS, IBM, Tibco Software sont des fournisseurs de solutions de BI centralisée, parmi de nombreux autres. Encore une fois, il ne s’agit dans cet ouvrage que de citer l’existence de ces solutions pour le cas où Power Pivot ne suffirait pas à analyser de la donnée ouverte, ce qui semble peu probable vu que les sources de données Open Data avec plus de quelques millions d’enregistrements sont en fait très rares.
2. Approches Big Data
Depuis quelques...