
Créer un Data Warehouse
Introduction
Après avoir soigneusement préparé et nettoyé nos données dans le chapitre Préparer vos données pour en exploiter le potentiel, nous sommes maintenant prêts à franchir une étape décisive : la construction d’un modèle de données robuste et efficace au sein de notre Data Warehouse (DWH). Cette phase est cruciale, car elle transforme nos données brutes en une ressource stratégique, permettant des analyses approfondies et une prise de décision basée sur des informations fiables et structurées.
Dans ce chapitre, nous explorerons les fondements théoriques et pratiques de la modélisation des données, en mettant l’accent sur les techniques spécifiques aux Data Warehouses. Nous aborderons les différentes approches de modélisation, telles que le schéma en étoile et le schéma en flocon, et discuterons de leur pertinence selon les contextes d’utilisation.
Nous examinerons également les concepts clés comme les tables de faits et les tables de dimensions, essentiels pour organiser efficacement les données et faciliter les analyses multidimensionnelles. Une attention particulière sera portée à l’optimisation des performances des requêtes et à la scalabilité du modèle, des aspects cruciaux pour gérer de grands volumes de données.
La dernière partie du chapitre (section Projet Data Warehouse) sera consacrée à la mise en pratique de ces concepts. Nous...
Les caractéristiques et les bénéfices d’un Data Warehouse
1. Les caractéristiques principales
Un Data Warehouse se distingue par quatre caractéristiques clés qui en font un outil puissant pour l’analyse et la prise de décision :
-
Orienté sujet : contrairement aux bases de données transactionnelles centrées sur les opérations quotidiennes, un DWH est conçu pour répondre aux questions analytiques spécifiques à un domaine métier. Il stocke des données liées à un sujet particulier (clients, produits, ventes, etc.), excluant les informations non pertinentes pour l’analyse. Cette focalisation thématique permet une visualisation simple et concise des données, optimisée pour répondre aux besoins décisionnels.
-
Intégré : un DWH centralise les données provenant de différentes sources au sein de l’organisation, qu’elles soient internes (systèmes CRM, ERP) ou externes. Il établit une convention de nommage et des attributs communs pour garantir la cohérence et la standardisation des données. Ce processus d’intégration facilite la recherche, la récupération et l’analyse des informations, offrant une vue unifiée et fiable de l’ensemble des données de l’entreprise.
-
Varie...
Les composants d’une architecture analytique
Les composants d’une architecture analytique moderne forment un écosystème complexe et interconnecté, chacun jouant un rôle crucial dans le traitement et l’exploitation des données. Parmi ces composants, trois éléments clés se distinguent : le data lake, la staging area, et le Data Warehouse, auxquels s’ajoutent des concepts complémentaires comme les Data Marts et les méthodologies de modélisation telles que data vault.
Le data lake représente une évolution significative dans le stockage des données. Contrairement aux approches traditionnelles, il permet de stocker des volumes massifs de données dans leur format brut, qu’elles soient structurées, semi-structurées ou non structurées. Cette flexibilité est particulièrement précieuse à l’ère du Big Data, où la diversité des sources et des formats de données ne cesse de croître. Le data lake offre une extensibilité remarquable, pouvant accueillir des données aussi variées que des transactions, des logs d’applications, des fichiers multimédias ou des données IoT.
L’un des avantages majeurs du data lake réside dans son approche schema-on-read, qui permet de stocker les données sans nécessiter de transformation...
Les différents types d’architecture d’un projet analytique
1. Architecture Single Tier
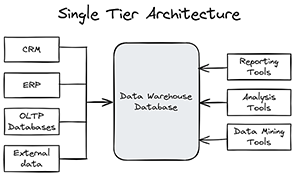
L’architecture Single Tier ou One Tier, également connue sous le nom d’architecture à niveau unique, représente la configuration la plus élémentaire d’un Data Warehouse. Cette approche simpliste regroupe toutes les composantes essentielles - stockage des données, traitement et présentation - au sein d’un seul et même système ou serveur. Bien que cette configuration puisse sembler attrayante par sa simplicité apparente, elle présente des limitations significatives qui en font une option sous-optimale pour la plupart des projets analytiques modernes.
Dans cette configuration, les données sont extraites directement de leurs sources d’origine et copiées telles quelles dans le Data Warehouse, sans passer par des étapes intermédiaires de transformation ou d’optimisation. Cette approche « brute » signifie que les données ne sont pas préparées spécifiquement pour les besoins analytiques, ce qui peut compliquer leur exploitation ultérieure. Les outils de Business Intelligence se connectent directement à ce Data Warehouse centralisé pour générer des rapports et des tableaux de bord. Cette connexion directe, bien que simple à mettre en place, peut engendrer une charge de travail considérable sur le système unique, notamment lors de l’exécution de requêtes complexes ou de la génération de visualisations élaborées.
Malgré ses inconvénients, l’architecture One Tier présente certains avantages qui peuvent la rendre attrayante dans des contextes spécifiques. Sa simplicité de mise en œuvre est indéniable : avec tous les composants sur un seul système, l’installation et la configuration initiales sont relativement simples. Cette approche peut également se traduire par des coûts initiaux réduits, l’utilisation d’un seul serveur permettant de limiter les investissements matériels et logiciels au démarrage du projet. Pour les petites structures ou les projets de taille modeste, la centralisation peut également simplifier la maintenance et l’administration...
Normalisation/dénormalisation
La normalisation et la dénormalisation sont deux approches fondamentales dans la conception des bases de données, chacune offrant des avantages spécifiques selon le contexte d’utilisation. La normalisation est un processus de structuration des données visant à éliminer les redondances et à garantir l’intégrité des données. Elle consiste à décomposer les tables complexes en tables plus petites et plus spécifiques, chacune ne contenant que des informations directement liées à son sujet principal. Ce processus, généralement appliqué jusqu’à la troisième forme normale (3NF), qui garantit que toutes les dépendances entre les données sont directement liées à la clé primaire de la table et qu’il n’existe pas de dépendances transitives, réduit la duplication des données, facilite les mises à jour et minimise les anomalies. Cependant, dans un contexte d’analyse où les performances de lecture sont cruciales, la normalisation peut entraîner une multiplication des jointures, ralentissant potentiellement les requêtes complexes.
À l’inverse, la dénormalisation est une technique qui consiste à combiner des tables ou à ajouter des données redondantes dans...
Différentes méthodes de design de DWH
1. Méthodologie de design Inmon
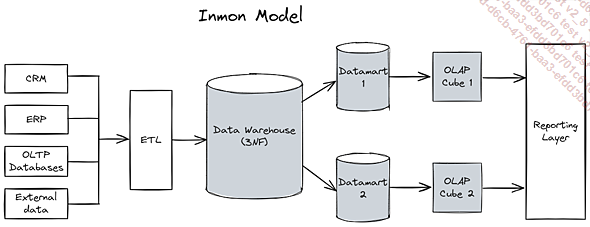
La méthodologie Inmon, également connue sous le nom d’approche top-down, est une stratégie de conception de Data Warehouse qui prône une vision holistique et intégrée des données de l’entreprise. Développée par Bill Inmon, considéré comme le « père du data warehousing », cette approche se distingue par sa volonté de créer une source unique de vérité pour l’ensemble de l’organisation.
Au cœur de la méthodologie Inmon se trouve le concept d’Enterprise Data Warehouse (EDWH), un référentiel centralisé qui agrège et normalise les données provenant de l’ensemble des systèmes opérationnels de l’entreprise. L’EDWH est conçu selon un modèle de données d’entreprise normalisé, généralement jusqu’à la troisième forme normale (3NF), ce qui garantit une structure cohérente et minimise la redondance des données.
À partir de cet EDWH, des Data Marts thématiques sont ensuite dérivés pour répondre aux besoins spécifiques des différents départements ou domaines d’activité. Ces Data Marts sont considérés comme des sous-ensembles du Data Warehouse central, assurant ainsi une cohérence globale des données à travers l’organisation.
L’un des principaux avantages de la méthodologie Inmon réside dans sa capacité à fournir une vue unifiée et cohérente des données de l’entreprise. Cette approche facilite grandement la prise de décision stratégique en offrant une compréhension globale et fiable des activités de l’organisation. De plus, la normalisation des données dans l’EDWH permet une gestion efficace des mises à jour et des modifications, tout en optimisant l’espace de stockage.
Cependant, la mise en œuvre de la méthodologie Inmon peut s’avérer complexe et coûteuse, notamment pour les organisations de taille moyenne ou les projets nécessitant une mise en production rapide. Le temps et les ressources...
Les différents types de tables dans un Data Warehouse
1. Les tables de faits (fact tables)
Les tables de faits sont au cœur de la modélisation dimensionnelle et contiennent les mesures quantitatives générées par les systèmes opérationnels de l’entreprise. Ces mesures sont essentielles pour l’analyse et la prise de décision, car elles permettent de créer des agrégations et de répondre à des questions clés sur les performances de l’entreprise.
Les tables de faits sont généralement identifiées par une clé primaire composite, formée par la combinaison des clés étrangères des tables de dimensions associées. Cette clé composite assure l’unicité de chaque enregistrement dans la table de faits et permet de lier les mesures aux dimensions correspondantes.
Types de colonnes de faits :
-
Additives : ces mesures peuvent être additionnées sur toutes les dimensions. Par exemple, la quantité de produits vendus peut être additionnée sur toutes les dimensions (temps, produit, client, etc.).
-
Semi-additives : ces mesures peuvent être additionnées sur certaines dimensions, mais pas sur toutes. Par exemple, le stock de produits peut être additionné sur la dimension produit, mais pas sur la dimension temps (car le stock varie dans...
Les schémas
1. Star Schema (schéma en étoile)
Le Star Schema est le schéma le plus couramment utilisé dans la modélisation dimensionnelle. Sa structure simple et intuitive facilite l’organisation des données dans le Data Warehouse. Il se compose d’une table de faits centrale, entourée de tables de dimensions qui lui sont reliées par des clés étrangères.
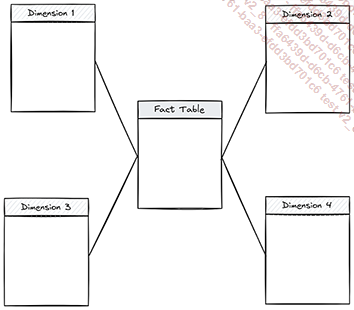
Cette façon de construire sa base possède plusieurs avantages :
-
Simplicité : le Star Schema est facile à comprendre et à utiliser, ce qui le rend idéal pour les utilisateurs métier qui ne sont pas nécessairement des experts en bases de données.
-
Performance : les requêtes sur un Star Schema sont généralement plus rapides que sur d’autres schémas, car elles impliquent moins de jointures entre les tables.
-
Facilité de requêtage : la structure simple du Star Schema facilite l’écriture de requêtes SQL pour extraire et analyser les données.
Par contre, cette structure n’est pas exempte de potentiels problèmes :
-
Redondance des données : le Star Schema peut entraîner une certaine redondance des données dans les tables de dimensions, ce qui peut augmenter l’espace de stockage requis.
-
Limitations de la modélisation : le Star Schema...
Projet Data Warehouse
Dans ce projet, vous allez créer un datawarehouse de A à Z avec Python et PostgreSQL. Nous allons utiliser un jeu de données Kaggle fourni par une enseigne brésilienne de supermarchés (Olist). Il existe deux versions de ce jeu de données, le modèle relationnel sous forme de fichier SQLite et un ensemble de fichiers CSV.
Votre commanditaire souhaite mettre en place un reporting hebdomadaire sur le suivi des commandes. L’idée est de partir de ce modèle relationnel pour le mettre en forme et créer un DWH de type Kimball focalisé sur les commandes.
1. Prérequis
La première chose à faire pour créer ce datawarehouse est d’installer PostgreSQL et de créer une base de données vierge. À l’heure actuelle, la dernière version de PostgresSQL est la version 14, c’est celle que nous utiliserons dans ce projet.
Nous allons réaliser les actions suivantes :
Installez postgreSQL.
Créez un utilisateur.
Créez une base de données.
a. Ubuntu
Étape 1 : téléchargement et installation de PostgreSQL 14
La première étape consiste à exécuter la commande suivante :
sudo apt-get -y install postgresql-14 Vous pouvez tester le bon fonctionnement de l’installation en lançant la commande suivante : sudo su - postgres puis psql.
Étape 2 : ajout d’un utilisateur
Passons maintenant à la deuxième étape, il nous faut créer un utilisateur.
postgres=# CREATE USER user WITH PASSWORD 'mot_de_passe'; Étape 3 : ajout d’une base de données
Enfin, nous pouvons créer notre base de données.
postgres=# CREATE DATABASE projet OWNER user; Nous pouvons vérifier maintenant que la base est bien créée. La commande \l permet d’afficher la liste des bases existantes :
postgres=# \l
Name | Owner | Encoding | Collate | Ctype |
Access privileges
-----------+----------+----------+-------------+-------------+
-----------------------
postgres | postgres | UTF8 | fr_FR.UTF-8 | fr_FR.UTF-8 |
projet | user | UTF8 ...


