
Introduction à REST
Présentation de REST
REST a été créé en 2000 par Roy T. Fieldling, également créateur du projet Apache HTTP Server et membre de la fondation Apache.
Il s’agit d’une architecture permettant à un client d’échanger avec un serveur de manière unitaire, très structurée et gérant le cache. Ainsi, il est possible de mettre en place des couches qui évoluent de manières autonomes.
Classiquement, dans le cas d’un contexte web (WWW - World Wide Web), tel qu’abordé dans ce livre, il s’agit d’une interface web pour le client, et d’une application de gestion de données pour le serveur, qui communiquent ensemble.
REST est indépendant du format représentant les données, que ce soit JSON, XML, ou une autre forme de sérialisation.
Une programmation stateless ou stateful ?
REST est-elle une architecture stateless (sans état) ou stateful (avec état) ?
La réponse est « stateless ». Il n’y a pas de notion de session (au sens large du terme) : le serveur ne se souvient pas des enchaînements des requêtes, ne fait pas varier les réponses selon un enchaînement particulier et ne stocke pas d’informations autres que les actions demandées sur les ressources (création, modification, suppression...).
REST vs RESTful
Vous trouverez au fil de vos lectures des mentions à des applications exposant leurs services en REST, et à d’autres applications exposant leurs services de manière RESTful.
Si une application est sans état, utilise uniquement des méthodes HTTP, expose sa structure dans les URI et qu’elle utilise dans ses requêtes du XML et/ou du JSON, elle respecte les différents préceptes de REST ; elle est donc RESTful.
En résumé, une application qui ne s’expose qu’en REST est RESTful. Si elle s’expose autrement, alors elle n’est pas RESTful.
Méthodes HTTP
Tout développeur ou intégrateur web connaît deux méthodes HTTP, à savoir GET et POST.
Dans l’usage courant des formulaires, les informations transmises avec la méthode par défaut (GET) passent en clair et sont visibles dans la barre d’adresse du navigateur, dans ce qu’on appelle la query string, tandis que les paramètres transmis avec un formulaire en précisant la méthode POST ne transparaissent pas dans la barre d’adresse, ni dans les logs Apache.
Une légende plaide dans le sens de l’utilisation de la méthode POST car la méthode GET serait limitée à 255 caractères, incluant la taille de la query string. La spécification RFC 2616 n’indique aucune exigence en ce sens.
Dans les faits, deux outils peuvent être à la source d’une éventuelle limitation, le navigateur utilisé et le serveur répondant à la requête.
Côté navigateur, même Internet Explorer, dont les anciennes versions ont souvent mauvaise réputation, de la version 4.0 édition 128 bits à la version 8, ne bride pas la taille de l’URL (Uniform Resource Locator) à 256 caractères mais à 2 083 caractères.
128 bits correspond au niveau de chiffrement du navigateur et non des performances de la machine et de son système d’exploitation.
Côté serveur, par défaut, le serveur Apache a une limitation par défaut à 8 190 octets, limitation qui peut être abaissée au choix de l’administrateur système.
La légende tient certainement sa source de la RFC 3986 qui indique que les programmes qui produisent des URI devraient si possible se limiter à 255 caractères, et à une syntaxe conforme à la syntaxe DNS (Domain Name System).
Il n’existe non pas deux mais onze méthodes HTTP, à savoir OPTIONS, HEAD, GET, POST, PUT, PATCH, DELETE, LINK, UNLINK, TRACE et CONNECT. Chaque méthode est liée à un usage spécifique.
Elles vont être détaillées dans les sections suivantes, à l’exception des méthodes TRACE et CONNECT, qui, mal utilisées, peuvent entraîner des failles de sécurité.
S’il fallait réduire...
En-têtes HTTP
Le but de ce livre n’est pas de fournir une liste exhaustive des en-têtes HTTP officiels, mais d’en ressortir quelques-uns intéressants dans le cas de l’implémentation d’une architecture de type REST.
1. Accept-Charset, Accept-Encoding et Transfer-Encoding
Pour pouvoir se comprendre, il faut commencer par parler la même langue. Les en-têtes Accept-Charset, Accept-Encoding et Transfer-Encoding permettent de s’assurer que le serveur et le client peuvent communiquer.
a. Accept-Charset
Accept-Charset indique le ou les jeux de caractères supportés par le client, séparés par des virgules. Des valeurs usuelles sont UTF-8 et ISO-8859-1. La valeur * signifie que n’importe quel jeu de caractères est accepté.
Chaque jeu de caractères peut être suivi par une valeur quantifiant la préférence avec laquelle le serveur voudra utiliser la donnée. Par défaut, cette valeur vaut 1.
Si le serveur ne peut pas répondre avec l’un des jeux de caractères demandés, il devrait répondre avec un code retour 406 (Not Acceptable).
Accept-Charset : ISO-8859-1;q=0.5, UTF-8
Accept-Charset : *
b. Accept-Encoding
Accept-Encoding indique les encodages supportés par l’application, séparés par des virgules. Les valeurs usuelles sont compress et gzip. La valeur * signifie que n’importe quel type d’encodage est accepté.
Comme dans le cas de l’en-tête Accept-Charset, chaque type d’encodage peut être suivi d’une valeur entre 0 et 1 désignant le niveau de préférence d’utilisation. Par défaut, cette valeur vaut 1.
Si le serveur ne peut pas répondre avec l’un des encodages demandés, il devrait répondre avec un code retour 406 (Not Acceptable).
Accept-Encoding : compress;q=0.5,gzip
Accept-Encoding : *
c. Transfer-Encoding
Dans la lignée de l’en-tête Accept-Encoding, Transfer-Encoding indique si une transformation du contenu a été opérée.
Des valeurs usuelles sont :
-
chunked...
Formats de sortie et leurs types MIME
Si, à l’origine, MIME (Multi-purpose Internet Mail Extensions) était un standard pour lister les types des données ajoutées à des e-mails, l’usage s’est élargi à toute forme de communication numérique, dont le protocole HTTP.
Les spécifications des types MIME sont actuellement décrites dans les RFC 4288 et 4289, et la liste des types MIME enregistrés est disponible sur le site de IANA (Internet Assigned Numbers Authority).
Un type MIME est composé de deux parties, le type et le sous-type, séparées par un /.
text/html
text/csv
application/json
application/xml
image/jpeg
Certains types permettent l’ajout d’informations complémentaires après le sous-titre. Cette information est optionnelle.
Ainsi, le type text peut être complété de l’encodage des caractères à l’aide de la variable charset.
text/html; charset=iso-8859-1
Format des URL, URL logiques et physiques
Lorsqu’une application web statique est créée, il est possible de la parcourir en suivant la structure de ses répertoires.
Ainsi, par défaut, si l’URL suivante est appelée, alors abc est un répertoire et def est un fichier d’extension ghi. Il s’agit d’une URL physique.
http://domaine/abc/def.ghi
Avec l’apparition des procédures d’URL rewriting (réécriture d’URL), que ce soit au travers de règles Apache, ou de par la structure dynamique de l’application, ce type d’URL se fait moins présent sur Internet. Les applications masquent la structure physique au profit de chaînes humainement compréhensibles, mieux référencées, et moins sensibles aux attaques. Ce sont des URL logiques.
Par exemple, dans le cas suivant : http://domaine/monArticleSurLaMusique remplace alors http://domaine/monBlog/lire.do?id=1234
L’identifiant de base de données est masqué (id=1234), la technologie Java est masquée (.do) et le nom de l’article (monArticleSurLaMusique) est directement référencé par les moteurs de recherche.
Liens vers les ressources
REST est une architecture centrée sur des ressources de l’application. Ces ressources sont lues et/ou modifiées à l’aide de verbes, qui sont les méthodes du protocole HTTP.
De manière générale, on peut dégager la structure de liens suivante.
Dans les exemples qui vont suivre, les liens seront composés uniquement de la partie gérée en REST (pas de nom de domaine, etc.).
Les appels pourront éventuellement être accompagnés de paramètres d’URL, ou d’en-têtes, pour filtrer les résultats.
1. Action sur l’ensemble des ressources d’un type
De manière usuelle, pour exécuter une action sur l’ensemble des ressources d’un type T, il faut appeler une URL de forme /T.
GET /TitreMusique
Un appel en méthode GET sur le lien /TitreMusique est un appel pour lire l’ensemble des objets de type TitreMusique disponibles.
2. Action sur une ressource donnée
Pour exécuter une action sur une ressource donnée d’un type T, il faut appeler une URL de forme /T en ajoutant ensuite une ou plusieurs variables discriminantes V pour obtenir une URL de forme /T/V.
GET /TitreMusique/1
Un appel en méthode GET sur le lien /TitreMusique/1 retourne le titre d’identifiant 1.
3. Action sur une ressource liée
Pour exécuter une action sur une ressource...
Gestion des exceptions
En cas d’erreur de traitement, le serveur fournissant les services REST génère une exception.
Il doit informer l’application appelante de l’erreur, et la première indication est de changer le code retour HTTP. Puis il faut s’efforcer d’apporter des détails dans le corps de la réponse, dans un format compris par le client.
1. Codes HTTP d’erreurs
Voici une liste des codes HTTP pouvant être utilisés.
Les codes de 300 à 307 correspondent à des erreurs de redirection, ceux de 400 à 417 correspondent à des erreurs liées à la requête formulée par le client, et ceux de 500 à 505 correspondent à des erreurs de traitement du serveur.
Code 300 (Multiple Choices)
L’URL qui a été appelée correspond à plusieurs ressources. Il faut reformuler la requête de manière à indiquer la ressource attendue.
Sauf dans le cas où la requête a été envoyée en méthode HEAD, le serveur devrait indiquer une liste de caractéristiques et URL permettant de distinguer les ressources.
Code 301 (Moved Permanently)
La ressource était, à un moment donné, accessible sur cette URL. Elle a depuis été déplacée. Le nouvel emplacement devrait être communiqué par le serveur à l’aide de l’en-tête Location.
Sauf dans le cas où la requête a été envoyée en méthode HEAD, le serveur devrait indiquer dans le corps de la réponse un code...
Test d’une requête REST
S’il est aisé de tester une requête en méthode GET depuis n’importe quel navigateur, il est aussi utile de pouvoir changer de méthode ou modifier des en-têtes, sans créer d’application dédiée.
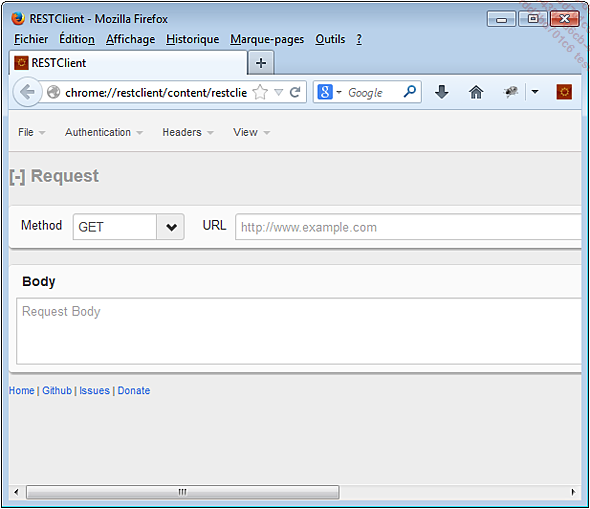
1. Sous Mozilla Firefox
RESTClient (http://restclient.net/) est un plugin pour Firefox qui permet de tester des requêtes REST.
Il prend en charge les méthodes GET, POST, PUT, DELETE, OPTIONS, HEAD, TRACE et CONNECT. Il manque donc éventuellement les méthodes PATCH, LINK et UNLINK.
Il permet de gérer l’authentification HTTP en méthode BASIC, ainsi que les autorisations OAuth en versions 1 et 2. Il ne gère donc pas l’authentification HTTP en mode DIGEST.
Il est possible d’insérer un corps de requête, mais aussi des en-têtes personnalisés.
Ce plugin gère l’enregistrement des en-têtes et des requêtes favoris, et permet d’exporter et d’importer des requêtes.
2. Sous Google Chrome
POSTMAN (http://www.getpostman.com/) est un plugin pour Google Chrome qui permet de tester des requêtes REST.
Il prend en charge les méthodes GET, POST, PUT, PATCH, DELETE, COPY, OPTIONS, HEAD, LINK, UNLINK, PURGE.
La méthode COPY est définie dans la RFC 2518 traitant des extensions HTTP, et sert à créer la copie d’une ressource....

