
Déploiement avec Kubernetes
Introduction
Dans les chapitres précédents, nous avons vu comment construire des images Docker de notre application et comment les déployer de façon semi-automatique sur nos serveurs grâce à des scripts Ansible. Avec un orchestrateur comme Kubernetes, nous savons maintenant comment nous affranchir des contraintes liées à un environnement statique, en le laissant choisir où déployer à notre place. Nous allons maintenant voir comment déployer eni-todo avec cet orchestrateur. Pour cela, il faut apprendre à utiliser certaines ressources.
Tous les exemples Kubernetes présentés dans ce chapitre et les suivants sont mis à disposition dans le repository github k8s_manifests.
Du pod aux déploiements
1. Pod
Nous avons vu qu’il est possible de créer un pod utilisant un container tomcat-eni-todo:v24.04-tomcat-h2-env. Nous utilisons tout d’abord cette version, nous ajouterons l’externalisation de la base de données plus tard.
Nous lançons donc un pod eni-todo-h2 avec le container utilisant cette image. Il faut s’assurer que le container a bien démarré et fonctionne correctement.
$ kubectl run eni-todo-h2 \
--image=registry.diehard.net:5000/tomcat-eni-todo:v24.04-tomcat-h2-env \
--env="
DB_DTB_JDBC_URL="jdbc:mysql://mariadb.diehard.net:3306/db_todo" \
--env="DB_DTB_USERNAME=springuser" ...
pod/eni-todo-h2 created Il est également possible de lancer le container avec un fichier YAML et la commande suivante :
$ kubectl apply -f eni-todo-h2.000.pod.yaml
pod/eni-todo-h2 created Les fichiers YAML utilisés dans ce chapitre sont dans le dossier src/main/kubernetes du dépôt git de l’application eni-todo (https://github.com/halnx-todo/k8s-manifests).
a. Sondes et contrôle de santé
Kubernetes offre un système de sonde permettant de vérifier la santé (healthcheck) d’un pod. Il y a trois types de sondes :
-
livenessprobe
-
readinessprobe
-
startupprobe
Toutes les trois se configurent de la même façon, avec des objets dans la définition du container.
Il existe trois mécanismes de sonde possibles :
-
tcpSocket : la kubelet présente sur le nœud vérifie que le container a bien ouvert le port défini dans les paramètres de cette sonde.
-
Exec : la kubelet présente sur le nœud vérifie que le script défini dans les paramètres de cette sonde s’exécute correctement (code retour 0) dans le container observé.
-
httpGet : la kubelet présente sur le nœud vérifie que l’appel HTTP défini dans les paramètres de cette sonde retourne un code retour tel que défini (200 par défaut).
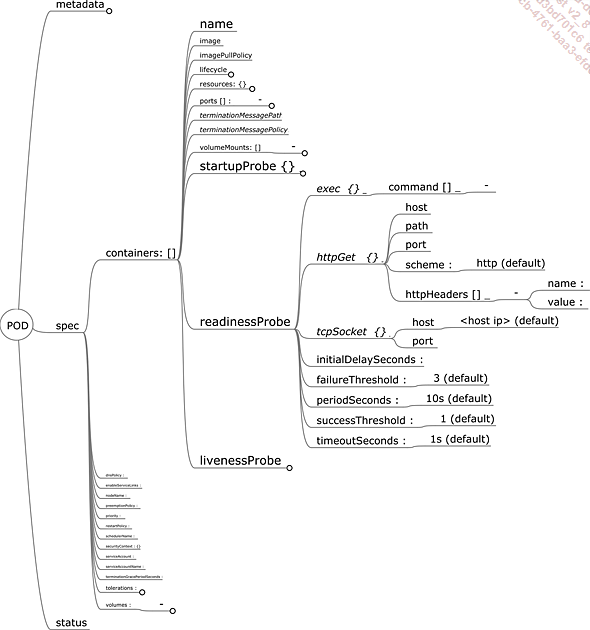
Figure 1 : Spécifications des sondes d’un pod
Les sondes ont :
-
un délai d’attente avant d’être activées (initialDelaySeconds) ;
-
une fréquence d’exécution (periodSeconds) ;
-
un seuil ou nombre...
Services et Endpoints
Nous sommes passés rapidement sur le besoin d’avoir plusieurs pods pour maintenir le service, mais c’est précisément cette redondance qui permet de maintenir cette haute disponibilité.
Il faut donc un mécanisme pour répartir les flux des requêtes vers les pods. C’est le rôle des objets Service. Cette abstraction est utilisée pour fournir les informations nécessaires au cluster afin de faire les configurations réseau permettant la communication dans le cluster et avec l’extérieur.
Comme nous l’avons évoqué dans les chapitres précédents, les labels sont utilisés pour permettre la sélection des objets dans Kubernetes. Le mécanisme des labels est omniprésent dans un cluster. Les labels sont également utilisés pour associer (mapping) les pods à un service via l’utilisation d’un sélecteur.
1. Service de type ClusterIP
Un service est donc une abstraction de Kubernetes pour permettre la résolution réseau et l’exposition des pods. Le DNS d’un service est de la forme :
<service>.<namespace>.svc.cluster.local Un Service permet également d’exposer l’application sur un port différent du port exposé par le pod, si nécessaire.
apiVersion: v1
kind: Service
metadata:
labels:
app: eni-todo
name: eni-todo
spec:
ports:
- port: 80
name: http8080
protocol: TCP
targetPort: 8080
selector:
app: eni-todo
sessionAffinity: ClientIP
type: ClusterIP Vous pouvez ensuite chercher les pods qui sont identifiés par des labels.
$ kubectl get po -l app=eni-todo
NAME READY STATUS RESTARTS AGE
eni-todo-95755d699-gldr6 1/1 Running 0 55m
eni-todo-95755d699-jrzrg 1/1 ...Secret et ConfigMap
Nous avons vu que nous écrivons les variables d’environnement directement dans la définition des pods (template de pod). Il est toujours préférable d’externaliser les fichiers de configuration, c’est à cela que servent ConfigMap et Secret.
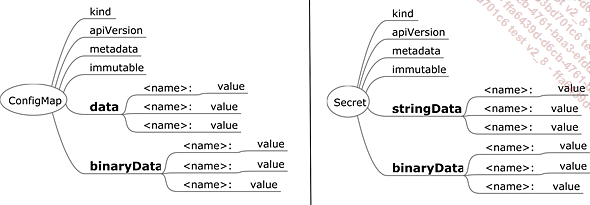
Figure 9 : ConfigMaps et Secret
Il est possible de stocker des couples variable/valeur dans des objets de type ConfigMap et Secret. Mais là où un ConfigMap stocke les informations directement au format texte et en clair, un secret demande une valeur encodée au format base64, par exemple :
mysql_root_password: cjAwdC1hZWtpZThhaHdhaV8= Le stockage dans la base etcd est également différent, car les secrets sont chiffrés dans la base si l’option est activée dans kube-apiserver (--encryption-provider-config).
L’encodage en base64 n’est pas un chiffrement sécurisé. Il s’agit d’un changement de référentiel de codage de l’information. Les informations binaires historiquement sur 8 bits passent sur 7 bits, c’est un chiffrement qui a pour but d’éviter les soucis de caractères spéciaux pouvant être mal interprétés lors des transferts réseau.
Il est également possible de stocker des fichiers dans les deux types d’objets.
Dans un ConfigMap :
apiVersion: v1
kind: ConfigMap
metadata:
name: mariadb-init
data:
init.sh: |
#!/bin/sh ...StatefulSet
Après avoir vu comment accéder à une base de données externe, nous allons voir comment mettre une base de données dans notre cluster.
Un pod peut s’instancier sur n’importe quel node en fonction des ressources disponibles. Si cela fonctionne très bien pour des services sans conservation de l’état (stateless), ce n’est pas le cas des bases de données dont le rôle même est la conservation des données.
Au début de Kubernetes, une astuce consistait à forcer l’exécution d’un pod sur un node précis via une sélection par l’attribut nodeName ou bien à utiliser les mécanismes de nodeAffinity ou nodeSelector, pour nous assurer qu’un pod était instancié sur le node ayant des répertoires dédiés au stockage des données du pod, que le pod pouvait monter directement avec hostpath.
apiVersion: v1
kind: Pod
metadata:
labels:
app: mariadb
name: mariadb
spec:
volumes:
- name: test-volume
hostPath:
path: /data/mariadb
type: DirectoryOrCreate
containers:
- image: mariadb:10.5.8
name: mariadb
nodeName: k8s-worker01
env:
- name: MYSQL_USER
value: "springuser"
- name: MYSQL_PASSWORD
value: "mypassword-quoor-uHoe7z"
- name: MYSQL_DATABASE
value: "db_todo"
- name: MYSQL_ROOT_PASSWORD
value: "r00t-aeKie8ahWai_"
volumeMounts:
- mountPath: /var/lib/mysql
name: test-volume
ports:
- name: mariadb
containerPort: 3306
protocol:...PersistentVolume
Comme nous l’avons évoqué plusieurs fois, Kubernetes est un orchestrateur qui sélectionne, parmi son pool de nodes et selon les critères qu’on lui a donnés, le node sur lequel instancier le pod. Cela signifie que pour apporter de la persistance de données, celle-ci doit pouvoir être utilisable par le pod sur n’importe quel node. Les containers constituant les pods vont devoir monter les volumes présents sur leur node. Le node lui-même ayant probablement un montage de système de fichier à réaliser en amont (NFS, Gluster FS, etc.). Les objets PersistentVolume et PersistentVolumeClaim fournissent aux clusters (node, kubelet…) les informations nécessaires pour réaliser ces différents montages de systèmes de fichier.
Cette mécanique est intrinsèquement liée aux technologies sous-jacentes et aux outils extérieurs au cluster. Cela dit, il existe des solutions de stockage utilisant un cluster Kubernetes, telles que Rook, GlusterFS ou OpenEBS, qui dédient au service de stockage des espaces de stockage des nodes du cluster, pour assurer la persistance des volumes de données qu’ils proposent et en assurer leur cohérence.
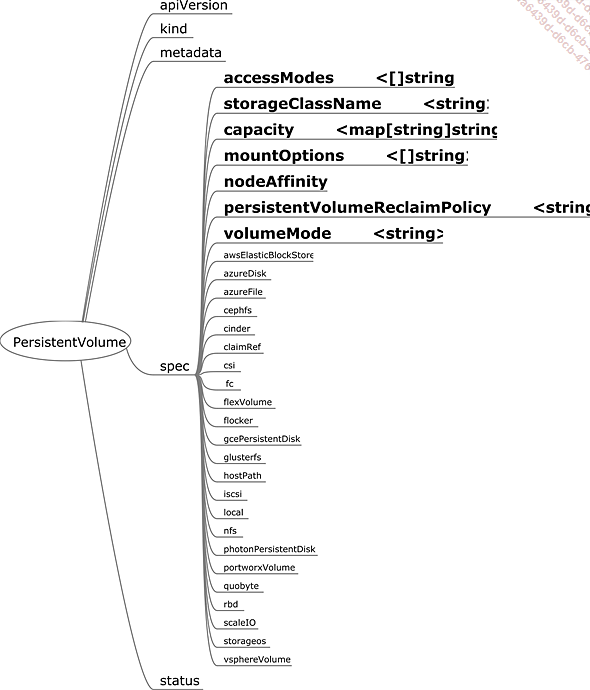
Figure 10 : Spécifications d’un volume persistant
Un volume persistant (Persistent Volume ou PV) dispose de plusieurs attributs :...
PersistentVolumeClaim
Une demande de volume persistant (Persistent Volume Claim ou PVC) est une sorte de contrat qui lie un volume persistant à un namespace. Lors de sa création, le cluster Kubernetes cherche à fournir un volume persistant correspondant aux besoins définis dans le PVC. Si d’aventure il possède la classe de stockage demandée, il l’utilise pour créer un nouveau PVC conforme à la définition de la classe demandée et aux besoins définis dans le PVC initial. Sinon, il recherche dans son pool de volumes persistants celui correspondant au mieux à la demande.
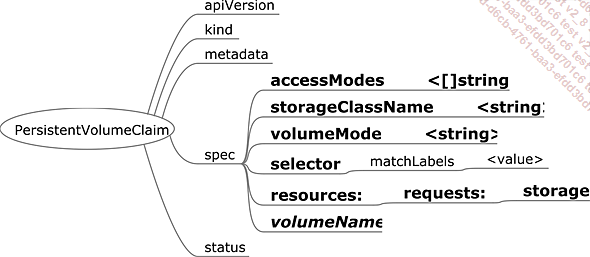
Figure 11 : Spécifications d’un PVC
Lors de l’affectation du PV au PVC, l’attribut claimRef du PV est renseigné avec les références du PVC (name).
StorageClass
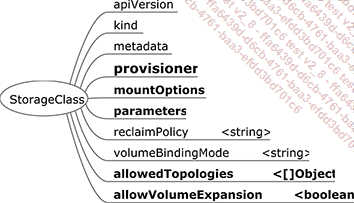
Figure 12 : Spécifications d’une classe de stockage
La classe de stockage (StorageClass) est la ressource permettant de fournir dynamiquement des PVC (et les PV derrière).
Elle a plusieurs attributs :
-
provisioner : le provisioner correspond au CSI (Container Storage Interface), le driver (pilote) utilisé pour réaliser la communication avec le serveur de stockage.
-
mountOptions : il s’agit des options passées par le nœud lors du montage du système de fichiers.
-
parameters : ce sont les paramètres nécessaires au driver.
-
reclaimPolicy : il s’agit de la définition du cycle de vie du PV affecté au PV créé avec cette classe de stockage (Delete, Retain ou Recycle).
-
volumeBindingMode : c’est la politique utilisée pour tracer le montage du volume entre le PVC appelant la classe de stockage et le PV créé par celle-ci.
-
Immediate : l’information liant le PV au PVC est créée avant l’utilisation de celui-ci.
-
WaitForFirstConsumer : l’information liant le PV au PVC est faite lors du montage du volume par un nœud.
-
allowedTopologies : il s’agit des labels autorisés pour les PV qui vont être créés. Cet attribut est utilisé principalement (pour les CSI qui le permettent) pour garantir que le volume est créé...
Routes ingress
1. Le contrôleur des flux entrant (ingress controller)
Comme nous l’avons vu précédemment, les services ne sont pas parfaitement adaptés aux serveurs web et à la notion d’hébergement mutualisé de services web (virtual hostname). Les services web sont généralement délivrés, par convention, sur les ports 80 et 443. De plus, de nombreux systèmes de sécurité bloquent des appels vers des ports non standards.
Pour les clusters Kubernetes hébergés par des fournisseurs de services cloud, il est possible d’utiliser les services de type load balancer, mais chaque service ouvert coûte alors le prix d’un répartiteur de charge du fournisseur.
Le contrôleur des flux entrant (ingress controller) est un contrôleur au sens Kubernetes, c’est-à-dire qu’il écoute les événements et réagit aux modifications de certains types de ressources - dans notre cas, les ressources ingress.
L’ingress controller instancie un ou plusieurs pods de reverse proxies avec des droits élevés (hostPort, NET_BIND_SERVICE) qui peuvent, si on les configure à cette fin, écouter sur les ports 80 et 443 des nodes sur lesquels ils tournent. Ces reverse proxies feront le routage des requêtes HTTP vers les services adéquats tels que définis...
Job et CronJob
Il est possible de lancer des tâches (jobs) dans Kubernetes. Les jobs sont uniques : ils ne sont joués qu’une seule fois.
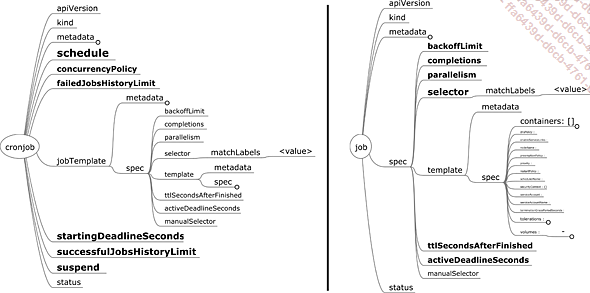
Figure 14 : Spécifications d’un Job et d’un CronJob
Les attributs du job sont les suivants :
-
backoffLimit est le nombre d’essais infructueux (exit !=0) avant de considérer le job comme étant en échec (fail).
-
completions est le nombre de pods qui doivent réussir (exit == 0) pour considérer le job comme étant réussi.
-
parallelism est le nombre de pods susceptibles d’être exécutés en même temps.
-
ttlSecondsAfterFinished est le temps d’attente avant de laisser les mécanismes de nettoyage supprimer les pods finis. Si l’attribut n’est pas défini, le job ne sera pas supprimé automatiquement.
-
activeDeadlineSeconds définit le temps d’attente avant d’essayer de supprimer le job.
Il est également possible d’avoir des tâches récurrentes programmées à certaines dates : les cronjobs.
Les attributs notables d’un cronjob sont les suivants :
-
schedule définit au format cron la périodicité d’exécution des jobs.
-
concurrencyPolicy définit la politique à suivre si la périodicité demande le lancement d’un nouveau job tandis que le job précédent n’est...
DaemonSet
Le DaemonSet est une ressource qui lance une instance unique de pod sur chacun des nodes du cluster correspondant à sa cible de selector.
Ses attributs notables sont les suivants :
-
minReadySeconds désigne le délai avant que le daemonset dont le pod est ready soit considéré comme ready.
-
revisionHistoryLimit désigne le nombre de versions de daemonset conservées.
-
updateStrategy définit la stratégie de mise à jour, comme pour les Deployment.
C’est un composant très important dans le cluster Kubernetes. Il est utilisé pour le déploiement des CNI (Container Network Interface) ou des CSI (Container Storage Interface) par exemple. Nous le reverrons dans les prochains chapitres.


![Linux Préparation à la certification LPIC-1 (examens LPI 101 et LPI 102) - [7e édition]](http://media1.editions-eni.fr/livre/linux-preparation-a-la-certification-lpic-1-examens-lpi-101-et-lpi-102-7e-edition-9782409043109_M.webp)

