
Les containers
Cahier des charges
Le chapitre Application standalone a révélé les défauts d’une architecture monolithique. Le chapitre Infrastructure et services de base a fourni les bases d’une infrastructure tolérante aux pannes et capable d’accueillir des applications dans de bien meilleures conditions. Il faut maintenant pouvoir déployer l’application sur les serveurs, le plus simplement et le plus rapidement possible. Il y a de nombreuses étapes à respecter pour l’installer, la configurer et la démarrer. Il est temps d’ajouter des éléments au cahier des charges :
-
L’application doit pouvoir être installée simplement.
-
L’application doit être réutilisable.
-
L’application doit pouvoir être déployée sur plusieurs serveurs.
-
Un même serveur doit pouvoir faire tourner plusieurs instances de l’application.
-
La maintenance de l’application doit être minimale.
-
L’application ne doit pas accaparer toutes les ressources du serveur.
Ce dernier point peut surprendre, et pourtant c’est aussi un élément de disponibilité et de tolérance aux pannes. Un processus qui consomme toutes les ressources CPU empêche le bon fonctionnement des autres applications et services.
S’il consomme toute la mémoire, il risque d’être...
Isolation et container
1. Principe
L’isolation est une technique consistant à exécuter des applications dans leurs propres contextes, isolés des autres. C’est une forme de virtualisation. La première implémentation de ce type sous Unix date de 1979, avec chroot.
L’isolation d’un ou de plusieurs processus est assurée par le noyau Linux à l’aide des deux mécanismes : les espaces de noms ou namespaces, et les groupes de contrôle ou cgroups. Les namespaces sont apparus en 2002, et les cgroups en 2007. Tout noyau Linux intègre ces fonctionnalités par défaut. L’arrivée des espaces de noms utilisateurs ou users namespaces dans le noyau 3.8 en février 2013 a ouvert la voie au support complet des conteneurs ou containers.
Les namespaces regroupent des processus dans un espace isolé des autres. Ils permettent d’avoir :
-
une isolation des processus et un processus de PID 1 comme premier processus dans son espace (PID 1 du premier processus d’un espace de noms) ;
-
une isolation du réseau, avec des adresses IP et des ports qui leur sont propres ;
-
une isolation des volumes de données : le stockage ;
-
une isolation des droits et des utilisateurs par rapport à l’hôte : être root au sein d’un container peut ainsi correspondre à un utilisateur sans pouvoir sur l’hôte.
Les cgroups contrôlent les ressources du système qu’un groupe de processus peut utiliser, avec par exemple les contrôles suivants :
-
limiter la consommation de la mémoire ;
-
limiter l’utilisation des processeurs ;
-
gérer les priorités ;
-
obtenir des informations « comptables » sur ce groupe ;
-
contrôler dans leur ensemble (arrêter, par exemple) plusieurs processus ;
-
isoler ce groupe, en l’associant à un espace de noms.
L’association de ces deux mécanismes est la base du principe du container.
2. Container et machine virtuelle
Les containers sont souvent comparés à des machines virtuelles pour en faciliter la compréhension, mais il s’agit de deux types de technologies de virtualisation bien distinctes. Le concept est différent.
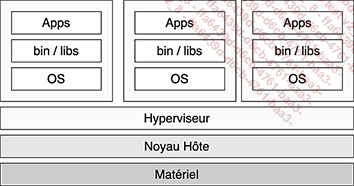
Figure 1 : Hyperviseur et machines virtuelles...
Préparer l’environnement
1. Installer Docker
Nous n’utiliserons pas la version diffusée par Ubuntu. Nous ajoutons un dépôt dans la configuration de apt.
Les exemples que nous allons présenter ont été testés avec une version 25.0.4. Avec une version inférieure à la 20.10.3, il vous faudra activer les fonctions expérimentales.
Il faut d’abord installer quelques dépendances. Il s’agit ici de démarrer proprement en retirant les packages éventuellement installés par la distribution, puis d’installer la clé GPG du dépôt, d’ajouter le dépôt officiel de Docker, de mettre à jour apt et enfin d’installer la version officielle.
Voici comment installer Docker.
On installe quelques dépendances préalables :
$ sudo apt install apt-transport-https ca-certificates curl
software-properties-common On ajoute la clé GPG du dépôt officiel :
$ sudo install -m 0755 -d /etc/apt/keyrings
$ sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o
/etc/apt/keyrings/docker.asc
$ sudo chmod a+r /etc/apt/keyrings/docker.asc On ajoute le dépôt officiel :
$ echo \
"deb [arch=$(dpkg --print-architecture) signed-
by=/etc/apt/keyrings/docker.asc]
https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
$ sudo apt update Enfin, on installe l’application Docker :
$ sudo apt-get install docker-ce docker-ce-cli containerd.io
docker-buildx-plugin docker-compose-plugin Il faut vérifier si le service est démarré :
~$ sudo systemctl status docker
● docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled;
preset: enabled)
Active: active (running) since Fri 2024-03-15 20:37:05 CET; 23min ago
TriggeredBy: ● docker.socket
Docs: https://docs.docker.com
Main PID: 855 (dockerd)
Tasks: 10
Memory: 116.7M
CPU: 404ms
CGroup: /system.slice/docker.service ...Construire l’image
1. Adaptation du code
Passer d’un modèle standalone ou on-premise (applications installées classiquement sur un serveur physique ou une machine virtuelle) à des containers, au cloud ou à Kubernetes ne résout pas magiquement tous les problèmes d’architecture, de montée en charge et de disponibilité d’une application. Sans une réflexion et une nécessaire adaptation de l’architecture et du code, l’opération risque de causer plus d’ennuis que d’en résoudre.
Une image se construit à l’aide d’un fichier Dockerfile dans lequel on précise toutes les commandes nécessaires à l’installation et au démarrage du produit. Comme l’explique le chapitre Application standalone, il y a plusieurs étapes de construction pour avoir une application fonctionnelle :
-
la construction de l’application elle-même avec Java, Maven, les profils, etc ;
-
l’installation et la configuration de Tomcat ;
-
la mise en place de l’application, la récupération du fichier WAR de la première étape et le démarrage de Tomcat.
Sachant qu’il n’y a pas besoin de tout l’environnement de construction (toutes les dépendances installées à la première étape), on ne va pas créer une image applicative avec tout ce contenu inutile. L’image finale ne doit contenir que le strict nécessaire pour démarrer l’application :
-
Java ;
-
les dépendances applicatives ;
-
Tomcat ;
-
l’application eni-todo.
Le programme est modifié pour accepter des paramètres via des variables d’environnement. Lors de la construction du fichier eni-todo.war, nous avons précisé des valeurs statiques pour l’accès à la base de données MariaDB. Maintenant, vous pouvez les préciser au démarrage avec les variables suivantes :
-
SPRING_PROFILES_ACTIVE : le profil Spring à utiliser.
-
MULTIPART_LOCATION : le chemin où stocker les pièces jointes aux tâches. Idéalement, un partage réseau pour la persistance.
-
DB_DTB_JDBC_URL : l’URL de connexion à la base de données, sous la forme jdbc:mariadb://<ip>/<base>....
Déployer les containers
1. MariaDB
MariaDB est une dépendance de l’application eni-todo. Pour le moment, nous laissons volontairement de côté la haute disponibilité de la base de données : nous verrons, dans la suite du fil rouge, et notamment dans le chapitre Déploiement avec Kubernetes et dans le chapitre Intégration finale, comment mettre en place une base de données sous forme de cluster. En attendant de disposer d’une version de MariaDB en haute disponibilité, nous pouvons :
-
réutiliser le service MariaDB installé au chapitre Application standalone, ce qui a été expliqué précédemment) ;
-
démarrer un service MariaDB sous forme de container.
Si vous réutilisez le service MariaDB existant, vous pouvez sauter cette section et passer directement à la section eni-todo.
a. Stockage
Les manipulations suivantes sont arbitrairement effectuées sur infra01.
MariaDB peut être démarré sous forme de container, dont les images sont fournies librement par la communauté Docker, sur le Docker Hub : https://hub.docker.com/_/mariadb
Comme expliqué précédemment, le container utilise son propre stockage via le montage en union, où la dernière couche est en écriture. Si nous démarrons un container MariaDB, la base de données sera créée dans le container, et à sa destruction, son contenu sera supprimé, définitivement perdu.
Docker permet de monter des volumes de données au sein d’un container. Il existe plusieurs types de montages. Nous allons utiliser un montage de type bind, qui permet d’associer un répertoire du système de fichiers hôte à un autre répertoire au sein du container : nous pourrons alors stocker la base de données sur l’hôte dans le répertoire /opt/mysql, que nous monterons dans le container dans /var/lib/mysql.
Commencez par stopper l’instance MariaDB si elle est démarrée sur infra01 :
$ sudo systemctl stop mariadb
$ sudo systemctl disable mariadb Créez le dossier sur le serveur :
$ sudo mkdir -p /opt/mysql /opt/mysql peut être aussi un partage réseau de type NFS ou CIFS, en provenance d’un NAS ou d’un...
Bilan
Nous sommes maintenant capables de démarrer notre application eni-todo sur plusieurs serveurs. Le partage NFS pour les fichiers téléchargés et une base de données commune et externe garantissent d’avoir le même état de l’application que nous y accédions depuis un serveur ou un autre, mais uniquement si nous stockons les informations en base : les informations utilisant les sessions ne sont accessibles que depuis l’instance de l’application où elles ont été créées.
Nous avons bien avancé, car nous pouvons maintenant facilement construire, déployer et réutiliser notre application sur plusieurs serveurs. Mais il nous reste plusieurs problèmes à résoudre :
-
La base de données est encore un point de défaillance unique (SPOF), car si l’instance unique de MariaDB tombe, l’application tombe en panne.
-
Pour le moment, le partage NFS provient d’une seule machine, et c’est aussi un point de défaillance unique : s’il tombe, les fichiers téléchargés deviennent inaccessibles.
-
On ne peut accéder à chaque container que de manière individuelle. Il faut une adresse IP unique qui répartit la connexion vers l’un des serveurs et containers.
-
Les sessions sont uniques par container déployé. Il faudrait...


![Linux Préparation à la certification LPIC-1 (examens LPI 101 et LPI 102) - [7e édition]](http://media1.editions-eni.fr/livre/linux-preparation-a-la-certification-lpic-1-examens-lpi-101-et-lpi-102-7e-edition-9782409043109_M.webp)

