
Objets de la base utilisant PL/SQL
Introduction
En plus des blocs PL/SQL anonymes utilisés par SQL*Plus ou par les outils de développement (Oracle*Forms, Oracle*Reports...), on peut utiliser le PL/SQL dans des objets de la base, comme les procédures stockées (PROCEDURE, FUNCTION, PACKAGE) et les déclencheurs de bases de données.
Les déclencheurs de bases de données
Un déclencheur ou trigger est un bloc PL/SQL associé à une table. Ce bloc s’exécutera lorsqu’une instruction du DML (INSERT, UPDATE, DELETE) sera demandée sur la table.
Le bloc PL/SQL qui constitue le trigger peut être exécuté avant ou après la mise à jour et donc avant ou après vérification des contraintes d’intégrité.
Les triggers offrent une solution procédurale pour définir des contraintes complexes ou qui prennent en compte des données issues de plusieurs lignes ou de plusieurs tables. Par exemple, pour garantir le fait qu’un client ne peut pas avoir plus de deux commandes non payées. Toutefois, les triggers ne doivent pas êtres utilisés lorsqu’il est possible de mettre en place une contrainte d’intégrité. En effet, les contraintes d’intégrité étant définies au niveau de la table et faisant partie de la structure de la table, la vérification du respect de ces contraintes est beaucoup plus rapide. De plus, les contraintes d’intégrité garantissent que toutes les lignes contenues dans la tables respectent ces contraintes, tandis que les triggers ne prennent pas en compte les données déjà présentes dans la table lorsqu’ils sont définis.
Le bloc PL/SQL associé au trigger peut être exécuté pour chaque ligne affectée par l’ordre DML (option FOR EACH ROW), ou bien une seule fois pour chaque commande DML exécutée (option par défaut).
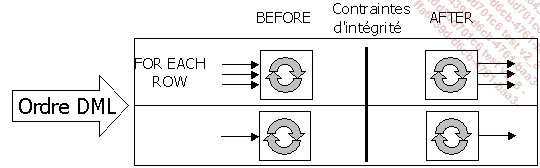
Exécution avant ou après vérification des contraintes d’intégrité pour chaque ligne ou chaque ordre.
Dans les triggers BEFORE et FOR EACH ROW, il est possible de modifier les données qui vont être insérées dans la table pour qu’elles respectent les contraintes d’intégrité. Il est également possible de faire des requêtes de type SELECT sur la table sur laquelle porte l’ordre DML uniquement dans le cadre d’un trigger BEFORE INSERT. Toutes ces opérations sont impossibles dans les triggers AFTER car après vérification des contraintes d’intégrité, il n’est pas possible de modifier...
Les triggers sur des événements système ou utilisateur
Il est possible d’utiliser les triggers pour suivre les changements d’état du système, tels que l’arrêt et le démarrage. Ces triggers vont permettre d’améliorer la gestion de la base et de l’application. En effet, certains événements systèmes ou utilisateurs ont un impact direct sur les performances de l’application et/ou la cohérence des données.
Les événements système sont l’arrêt et le démarrage de l’instance Oracle (startup et shutdown) et la gestion des erreurs. Les triggers d’arrêt et de démarrage ont comme portée l’ensemble de l’instance Oracle, tandis que le trigger de gestion des erreurs peut être défini soit au niveau du schéma soit au niveau de la base de données.
Au niveau de l’utilisateur, des triggers peuvent exister pour ses opérations de connexion et de déconnexion (logon et logoff), pour surveiller et contrôler l’exécution des ordres du DDL (CREATE, ALTER et DROP) et du DML (INSERT, UPDATE et DELETE).
Les triggers DML sont associés à une table et à un ordre du DML, leur définition et utilisation a été détaillée précédemment dans ce chapitre.
Lors de l’écriture de ces triggers, il est possible d’utiliser des attributs pour identifier précisément l’origine de l’événement et adapter les traitements en conséquence.
1. Les attributs
ora_client_ip_address
Permet de connaître l’adresse IP du poste client à l’origine de la connexion.
ora_database_name
Nom de la base de données.
ora_des_encrypted_password
Permet de connaître les descripitions codées du mot de passe de l’utilisateur qui vient d’être créé ou modifié.
ora_dict_obj_name
Nom de l’objet sur lequel...
Les modifications de triggers
Il n’est pas possible de modifier un trigger de base de données. Par contre, il est possible de le supprimer puis de le récréer ou bien de le créer avec l’option OR REPLACE.
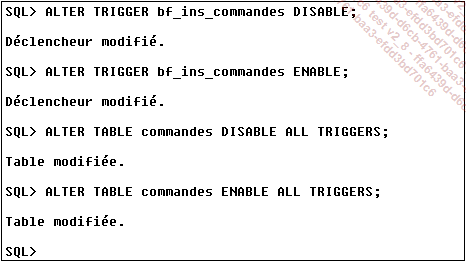
La commande ALTER TRIGGER va permettre en réalité de désactiver puis de réactiver les triggers. La désactivation peut être envisagée lors d’un import massif de données ou bien d’une modification de grande envergure.
La désactivation et la réactivation de trigger peuvent être réalisées trigger par trigger ou bien table par table. En effet, la commande ALTER TABLE permet l’activation et la désactivation de tous les triggers posés sur la table.
Syntaxe
ALTER TRIGGER nom_trigger {ENABLE|DISABLE};
ALTER TABLE nom_trigger { ENABLE|DISABLE } ALL TRIGGERS;
Exemple
Désactivation puis réactivation de triggers :
Pour obtenir des informations sur les triggers il faut interroger le dictionnaire de données. Les trois vues du dictionnaire à utiliser sont : USER_TRIGGERS, ALL_TRIGGERS et DBA_TRIGGERS.
La colonne BASE_OBJECT_TYPE permet de savoir si le trigger est basé sur une table, une vue, un schéma ou la totalité de la base de données.
La colonne TRIGGER_TYPE permet de savoir s’il s’agit d’un trigger BEFORE, AFTER ou INSTEAD...
Les procédures stockées
Une procédure stockée est un bloc de code PL/SQL nommé stocké dans la base de données et qui peut être exécuté à partir des applications ou d’autres procédures stockées. Dans un bloc PL/SQL, il suffit de référencer la procédure par son nom pour l’exécuter. À partir de l’outil SQL*Plus, on peut utiliser l’instruction EXECUTE.
Syntaxe
CREATE [OR REPLACE] PROCEDURE nom procédure
[(paramètre {IN/OUT/IN OUT} type, ...)]
{IS/AS} bloc PL/SQL ;
OR REPLACE
Remplace la description si la procédure existe.
paramètre
Variable passée en paramètre, utilisable dans le bloc.
IN
Le paramètre est passé en entrée de procédure.
OUT
Le paramètre est valorisé dans la procédure et renvoyé à l’environnement appelant.
type
Type de variable (SQL ou PL/SQL).
Exemple
Procédure de suppression d’un article :
SQL> create or replace procedure supp_art (numero in char) is
2 begin
3 delete from ligcdes where refart=numero;
4 delete from articles where refart=numero;
5 end;
6 /
Procédure créée.
SQL>
Utilisation par SQL*Plus...
Les fonctions stockées
Comme les procédures, une fonction est un ensemble de code PL/SQL, mais la fonction renvoie une valeur. Ces fonctions stockées seront utilisées comme les fonctions Oracle.
Syntaxe
CREATE [OR REPLACE] FUNCTION nom de fonction
[(paramètre [IN] type, ...)]
RETURN type {IS/AS} Bloc PL/SQL ;
OR REPLACE
La description est remplacée si la fonction existe.
paramètre
Paramètre passé en entrée utilisé comme une variable dans le bloc.
type
Type du paramètre (SQL ou PL/SQL).
RETURN type
Type de la valeur retournée par la fonction.
Exemple
Fonction factorielle :
CREATE FUNCTION factorielle (n IN NUMBER)
RETURN NUMBER
IS BEGIN
if n = 0 then
return (1) ;
else
return ((n * factorielle (n-1))) ;
end if ;
END ;
Utilisation par SQL*Plus :
SQL> Select factorielle (5) from DUAL ;
FACTORIELLE (5)
---------------
120
SQL>
Depuis la version 11, il est possible d’indiquer à Oracle de conserver en mémoire le résultat de l’appel d’une fonction. Lorsque cette fonctionnalité est activée pour une fonction, à chaque fois que celle-ci est appelée avec des valeurs différentes des paramètres, Oracle stocke en cache la valeur des paramètres et le résultat de la fonction. Lorsque cette fonction est de nouveau appelée ultérieurement avec les mêmes valeurs...
Les packages
Un package est un objet du schéma qui regroupe logiquement des éléments PL/SQL liés, tels que les types de données, les fonctions, les procédures et les curseurs.
Les packages se divisent en deux parties : un en-tête ou spécification et un corps (body). La partie spécification permet de décrire le contenu du package, de connaître le nom et les paramètres d’appel des fonctions et des procédures. Mais le code n’est pas présent dans la spécification. On trouve le code dans la partie body du package. Cette séparation des spécifications et du code permet de déployer un package sans que l’utilisateur puisse visualiser le code et permet de plus de faire évoluer simplement le code pour répondre à de nouvelles règles.
Les packages offrent de nombreux avantages :
Modularité
Le fait de regrouper logiquement les éléments PL/SQL liés rend plus facile la compréhension des différents éléments du package et leur utilisation en est simplifiée.
Simplification du développement
Lors de la mise en place d’une application, il est possible dans un premier temps de définir uniquement la partie spécification des packages et réaliser ainsi les compilations. Le corps du package ne sera nécessaire que pour l’exécution de l’application.
Informations cachées
Avec un package, il est possible de rendre certains éléments invisibles à l’utilisateur du package. Cela permet de construire des éléments qui ne peuvent être utilisés qu’à l’intérieur du package et donc l’écriture du package s’en trouve simplifiée.
Ajout de fonctionnalités
Les variables et curseurs publics du package existent durant la totalité de la session, donc, il est possible par cet intermédiaire de partager des informations entre les différents sous-programmes d’une même session.
Amélioration des performances
Le package est présent en mémoire dès le premier appel à un élément qui le compose. L’accès aux différents éléments du package est donc beaucoup plus rapide que l’appel à...
Les transactions autonomes
Une transaction est un ensemble d’ordres SQL qui constitue une unité logique de traitement. Soit la totalité des instructions de l’unité est exécutée avec succès soit aucune instruction n’est exécutée. Dans certaines applications, une transaction doit s’exécuter à l’intérieur d’une autre transaction.
Une transaction autonome est une transaction indépendante qui est lancée depuis une autre transaction : la transaction principale. Durant l’exécution de la transaction autonome, la transaction principale est suspendue.
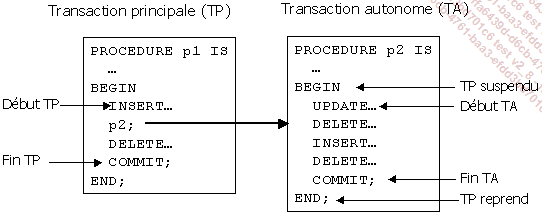
Les transactions autonomes sont totalement indépendantes, et cette indépendance permet de construire des applications plus modulaires. Bien sûr, les transactions autonomes présentent les mêmes caractéristiques que les transactions régulières.
Pour définir une transaction autonome, il faut utiliser la directive de compilation (pragma) AUTONOMOUS_TRANSACTION. Cette directive doit apparaître dans la section de déclaration des variables, des blocs PL/SQL anonymes, des fonctions, des procédures et des triggers. En règle générale, les directives de compilation sont placées en début de la section de déclaration des variables, ce qui facilite la relecture du programme.
Il n’est...
SQL dynamique
Le SQL dynamique est une technique qui permet de construire des ordres SQL de façon dynamique à l’exécution de code PL/SQL. Le SQL dynamique permet de créer des applications plus souples car les noms des objets utilisés par un bloc PL/SQL peuvent être inconnus au moment de la compilation. Par exemple, une procédure peut travailler avec une table dont le nom est inconnu avant l’exécution de la procédure.
Il faut rappeler que dans le SQL statique toutes les informations sont connues au moment de la compilation et bien sûr les ordres SQL statiques ne changent pas d’une exécution à une autre. Toutefois cette solution offre des avantages car le succès de la compilation garantit que les ordres SQL font référence à des objets valides de la base de données. La compilation vérifie également que les privilèges nécessaires sont en place pour accéder et travailler avec les objets de la base de données. De plus, la performance du code SQL statique est de meilleure qualité que celle du SQL dynamique.
À cause de tous ces avantages, le SQL dynamique ne doit être utilisé que si le SQL statique ne peut pas répondre à nos besoins, ou bien si la solution en statique est beaucoup plus compliquée qu’en SQL dynamique.
Cependant, le SQL statique possède certaines limites qui sont dépassées par le SQL dynamique. On choisira le SQL dynamique si par exemple on ne connaît pas à l’avance les ordres SQL qui vont devoir être exécutés par le bloc PL/SQL, ou bien si l’utilisateur doit donner des informations qui vont venir construire les ordres SQL à exécuter.
De plus, par l’intermédiaire du SQL dynamique, il devient possible d’exécuter des instructions du DDL (CREATE, ALTER, DROP, GRANT et REVOKE) ainsi que les commandes ALTER SESSION et SET ROLE à l’intérieur du code PL/SQL, ce qui est impossible avec le SQL statique.
Le SQL dynamique sera donc utilisé pour répondre à l’un des points suivants :
-
La commande SQL n’est pas connue au moment de la compilation.
-
L’ordre à exécuter n’est pas supporté par le SQL statique.
-
Pour exécuter des requêtes...
Collections et enregistrements
Dans le chapitre précédent, la déclaration et l’initialisation des collections et des enregistrements ont été abordées. Ce type de variable est très pratique et une bonne connaissance de leur utilisation permet souvent de gagner du temps lors de l’écriture de traitements en PL/SQL.
L’utilisation des tableaux en PL/SQL n’est pas forcément évidente au premier abord. En effet, pourquoi s’obliger à utiliser une telle structure alors que pour stocker un ensemble d’informations, il est très facile de créer une table temporaire.
La raison est très simple : en stockant l’ensemble des données sous forme de collection directement dans le bloc PL/SQL, tous les traitements peuvent être effectués par le moteur PL/SQL. En limitant les requêtes SQL, on limite les accès à la base, ce qui permet d’accélérer le temps de traitement du bloc PL/SQL, mais on limite également l’occupation du moteur SQL et les requêtes des autres utilisateurs peuvent donc être traités plus rapidement.
On voit donc qu’il existe des bénéfices à travailler avec les collections même si dans un premier temps le code PL/SQL à mettre en place est un peu plus compliqué. Il est à noter que l’instruction FORALL (vue plus loin dans ce chapitre) permet de faciliter considérablement les étapes de codages nécessaire pour pouvoir travailler avec les collections dans un bloc PL/SQL.
1. Référencer un élément d’une collection
Pour pouvoir travailler avec une collection, il faut d’abord savoir comment accéder à un élément d’une collection. Toutes les références possèdent la même structure : le nom de la collection suivi d’un indice entre parenthèses.
nom_collection (indice)
L’indice doit être un nombre valide compris entre -231+1 et 231-1.
Pour les collections de type nested table, la plage normale des indices va de 1 à 231-1 et pour les tableaux (VARRAY) elle va de 1 à la taille maximale du tableau.
Il est possible de faire référence à un élément d’une collection partout où...
La copie des données par blocs
Complètement intégré au SGBDR Oracle, le moteur procédural PL/SQL traite toutes les commandes procédurales et le moteur SQL s’occupe de traiter toutes les commandes SQL. L’interaction entre les deux moteurs est fréquente car le code PL/SQL travaille avec des données issues de la base de données, et extraites par l’intermédiaire de commandes SQL.
Lors de chaque passage du moteur PL/SQL au moteur SQL, et inversement, une charge de travail supplémentaire est demandée au serveur. Afin d’améliorer les performances, il est important de réduire ce nombre de changements de moteur. Les copies de données par blocs offrent une solution pour réduire le nombre d’interactions entre ces deux moteurs.
Répartition du travail entre les deux moteurs :
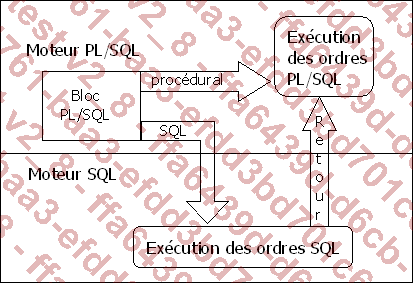
Avec les copies par blocs, les ordres SQL vont pouvoir concerner toute la collection et non seulement les éléments les uns après les autres.
L’exemple suivant, qui concerne l’insertion de lignes dans une table, permet de comparer le gain de temps entre le traitement classique des ordres SQL dans les blocs PL/SQL et le traitement par blocs.
Création de la table Composants :
La table créée ci-dessus va être remplie par l’intermédiaire d’un bloc PL/SQL. Pour chacune des deux méthodes d’insertion, le temps d’exécution sera mesuré.
Les avantages du traitement par blocs :
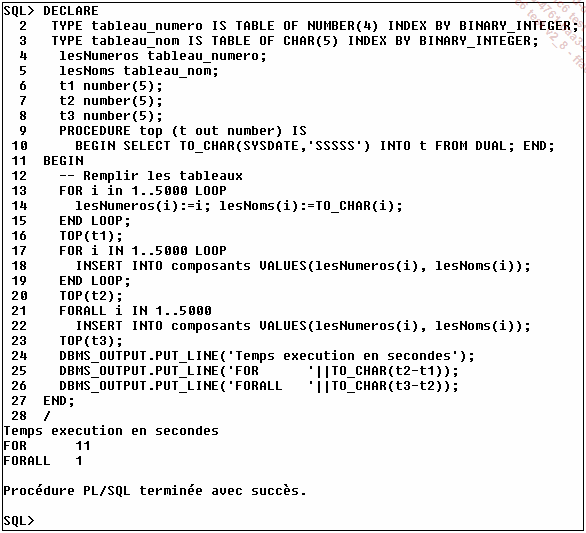
Pour traiter tous les éléments d’une collection, il faut utiliser le mot clé FORALL. Son utilisation est détaillée ultérieurement.
L’utilisation du package DBMS_OUTPUT est traité plus loin dans cet ouvrage. Pour pouvoir exécuter ce script correctement, il faut commencer par positionner la variable d’environnement SERVEROUTPUT à On dans SQL*Plus par l’intermédiaire de la commande : SET SERVEROUTPUT ON.
1. FORALL
Le mot clé FORALL indique au moteur PL/SQL de travailler par blocs avec la collection avant d’envoyer la commande SQL au moteur SQL. Bien que le mot clé FORALL propose une borne de début et de fin, il ne permet pas de mettre en place une boucle FOR.
Syntaxe
FORALL index IN borne_inférieur..borne_supérieur
commande_SQL;
La commande...
Fonctions et ensembles de lignes
Il est maintenant possible de définir en PL/SQL des fonctions qui acceptent en paramètres d’entrée et/ou qui retournent non pas une valeur simple mais un ensemble de lignes. L’avantage de ces fonctions est qu’il n’est alors plus nécessaire de stocker les données dans une table temporaire avant d’appeler l’exécution de la fonction. Il est possible d’utiliser de telles fonctions à tous les endroits où il est possible de faire référence à un nom de table et notamment avec la clause FROM d’une requête SELECT.
Afin d’améliorer les temps de réponses de ces fonctions qui retournent un ensemble de données, l’instruction pipelined précise que les données vont être retournées au fur et à mesure de l’exécution de la fonction. C’est d’ailleurs avec ce type de fonction que la gestion des ensembles de valeurs renvoyées est la plus simple.
Lors de la déclaration de la fonction, le mot clé PIPELINED est ajouté dans l’en-tête et les informations sont retournées à l’aide de la commande PIPE ROW.
Ces fonctions peuvent accepter en paramètre d’entrée un ensemble de lignes sous la forme d’une collection (comme un tableau de type VARRAY) ou bien sous la forme...
L’utilitaire Wrap
L’utilitaire Wrap est un programme qui permet de coder le code source PL/SQL. Il est ainsi possible de distribuer du code PL/SQL sans que les utilisateurs puissent avoir accès au code source.
Wrap va donc permettre de masquer l’algorithme utilisé mais en aucun cas les chaînes de caractères, les nombres, le nom des variables, des colonnes et des tables ne sont codés. L’utilitaire ne permet donc pas de masquer les mots de passe ou bien les noms des tables.
Cet utilitaire est entièrement compatible avec Oracle. La compatibilité descendante n’est pas assurée.
Cet utilitaire accepte deux paramètres :
iname
Permet de préciser le fichier qui contient le code PL/SQL qui va être codé.
oname (optionnel)
Permet de spécifier le nom du fichier qui va contenir la version codée du fichier précisé à l’aide de iname. Par défaut, ce fichier de sortie porte l’extension plb.
Syntaxe
wrap iname=fichier_entrée [oname=fichier_sortie]
Exemple d’utilisation de l’utilitaire Wrap

DBMS_OUTPUT
Le package DBMS_OUTPUT permet d’envoyer des messages depuis une procédure, une fonction, un package ou un déclencheur (trigger) de base de données. Les procédures PUT et PUT_LINE de ce package permettent de placer des informations dans un tampon qui pourra être lu par un autre bloc PL/SQL qui utilisera la procédure GET_LINE pour récupérer l’information.
Si la récupération et l’affichage des informations placées dans le tampon ne sont pas gérés et si l’exécution ne se déroule pas sous SQL*Plus, alors les informations sont ignorées. Le principal intérêt de ce package est de faciliter la mise au point des programmes.
SQL*Plus possède le paramètre SERVEROUTPUT qu’il faut activer à l’aide de la commande SET SERVEROUTPUT ON pour connaître les informations qui ont été écrites dans le tampon.
1. ENABLE
Cette procédure permet d’activer les appels aux procédures PUT, PUT_LINE, NEW_LINE, GET_LINE et GET_LINES. L’appel à cette procédure sera ignoré si le package DBMS_OUTPUT n’est pas activé.
Il n’est pas nécessaire de faire appel à cette procédure lorsque le paramètre SERVEROUTPUT est fixé depuis SQL*Plus.
Syntaxe
DBMS_OUTPUT.ENABLE (taille_tampon IN INTEGER...Le package UTL_FILE
Le package PL/SQL UTL_FILE permet aux programmes PL/SQL de travailler en lecture et écriture avec des fichiers texte du système de fichiers. Le flux d’entrée/sortie ouvert vers le système d’exploitation est limité au seul travail avec ces fichiers.
Côté serveur, l’exécution du programme PL/SQL qui travaille avec le package UTL_FILE, doit être réalisée dans un mode de sécurité privilégié, et d’autres options de sécurité limitent la possibilité des actions menées au travers de UTL_FILE.
Historiquement, côté serveur, les répertoires accessibles par UTL_FILE devaient être précisés dans le fichier des paramètres (INIT.ORA) par l’intermédiaire du paramètre UTL_FILE_DIR.
Syntaxe
UTL_FILE_DIR=c:\temp.
Pour rendre tous les répertoires accessibles par UTL_FILE côté serveur, il faut préciser le paramètre suivant dans le fichier INIT.ORA : UTL_FILE_DIR=*
À partir la version 9i il est préférable d’utiliser la commande CREATE DIRECTORY pour gérer les répertoires accessibles depuis le package UTL_FILE à la place du paramètre d’initialisation UTL_FILE_DIR.
Il est possible de connaître la liste des répertoires définis sur le serveur à l’aide de la vue ALL_DIRECTORIES.
Syntaxe
CREATE OR REPLACE DIRECTORY nom_repertoire AS 'chemin';
Un exemple d’utilisation de cette instruction est donné dans l’exemple récapitulatif du package.
1. FOPEN, FOPEN_NCHAR
Cette fonction permet d’ouvrir un fichier en vue d’effectuer des opérations de lecture ou d’écriture. Le chemin d’accès au fichier doit correspondre à un répertoire valide défini à l’aide de CREATE DIRECTORY.
Le chemin complet d’accès doit exister, et FOPEN ne peut pas créer de répertoires.
La fonction FOPEN retourne un pointeur sur le fichier. Ce pointeur devra être précisé pour l’ensemble des opérations de lecture/écriture qui seront effectuées par la suite.
Il n’est pas possible d’ouvrir plus de 50 fichiers de façon simultanée.
Syntaxe...
Le package DBMS_LOB
Les initiales LOB permettent d’identifier les objets de grande dimension (Large OBject).
Le travail avec les éléments de grande dimension (BLOB : Binary LOB, CLOB : Character LOB, NCLOB : uNicode CLOB et BFILE : fichier binaire) n’est pas aussi facile qu’avec les données de type plus classique (caractère, nombre, date). Le langage PL/SQL permet de travailler avec ces données à partir du moment où elles sont présentes dans la base mais les opérations de chargement depuis un fichier du système d’exploitation de comparaison ou de modification ne peuvent être réalisées qu’à l’aide du package DBMS_LOB.
1. Les constantes
Les constantes suivantes sont définies dans le package DBMS_LOB. Leur utilisation permet de clarifier l’utilisation des différentes fonctions et procédures du package.
file_readonly CONSTANT BINARY_INTEGER :=0;
lob_readonly CONSTANT BINARY_INTEGER :=0;
lob_readwrite CONSTANT BINARY_INTEGER :=1;
lobmaxsize CONSTANT INTEGER :=18446744073709551615;
call CONSTANT PLS_INTEGER :=12;
session CONSTANT PLS_INTEGER :=10;
2. APPEND
Cette procédure permet d’ajouter la totalité de la variable LOB d’origine à la variable LOB de destination.
Syntaxe
DBMS_LOB.APPEND(
destination IN OUT NOCOPY BLOB,
source IN BLOB);
DBMS_LOB.APPEND(
destination IN OUT NOCOPY CLOB CHARACTER SET ANY_CS,
source IN CLOB CHARACTER SET destination%CHARSET);
3. CLOSE
Cette procédure permet de fermer un élément LOB interne ou externe qui a été ouvert précédemment.
Syntaxe
DBMS_LOB.CLOSE(
{lob_origine IN OUT NOCOPY BLOB
| lob_origine IN OUT NOCOPY CLOB CHARACTER SET ANY CS
| fichier_origine IN OUT NOCOPY BFILE);
4. COMPARE
Cette fonction permet de comparer deux LOB dans leur totalité ou partiellement. Il est uniquement possible de comparer des LOB de même type (BLOB, CLOB ou BFILE). Pour les fichiers (BFILE)...

