
PL/SQL
Introduction
1. Qu’est-ce que le PL/SQL ?
Le PL/SQL est le langage procédural d’Oracle. Il constitue une extension au SQL qui est un langage ensembliste.
L’intérêt du PL/SQL est de pouvoir mélanger la puissance des instructions SQL avec la souplesse d’un langage procédural dans un même traitement.
Ces traitements peuvent être exécutés, soit directement par les outils Oracle (blocs anonymes), soit à partir d’objets de la base (procédures stockées et packages).
Les avantages du PL/SQL sont multiples :
-
Intégration du SQL : les instructions du DML, du transaction control et les fonctions SQL peuvent être utilisées avec pratiquement la même syntaxe.
-
Traitements procéduraux : la gestion des variables et les structures de contrôle (test, boucles) accroissent les possibilités de gestion des données.
-
Fonctionnalités supplémentaires : la gestion des curseurs et le traitement des erreurs offrent de nouvelles possibilités de traitements.
-
Amélioration des performances : plusieurs instructions sont regroupées dans une unité (bloc) qui ne générera qu’un "accès" à la base (à la place d’un accès par instruction).
-
Incorporation aux produits Oracle : les blocs ou procédures PL/SQL sont compilés et exécutés...
Gestion des variables
Les variables sont des zones mémoires nommées permettant de stocker une valeur.
En PL/SQL, elles permettent de stocker des valeurs issues de la base ou de calculs, afin de pouvoir effectuer des tests, des calculs ou des valorisations d’autres variables ou de données de la base.
Les variables sont caractérisées par :
-
leur nom, composé de lettres, chiffres, $, _ ou #. Un maximum de 30 caractères est possible. Ce ne doit pas être un nom réservé.
-
leur type, qui détermine le format de stockage et d’utilisation de la variable.
Les variables doivent être obligatoirement déclarées avant leur utilisation.
Comme SQL, PL/SQL n’est pas sensible à la casse. Les noms des variables peuvent donc être saisis indifféremment en minuscules ou en majuscules.
1. Variables locales
Déclaration
PL/SQL dispose de l’ensemble des types utilisables dans la définition des colonnes des tables dans le but de faciliter les échanges de données entre les tables et les blocs de code. Cependant, les étendues des valeurs possibles pour chacun de ces types peuvent être différentes de celles du SQL.
Il dispose également d’un certain nombre de types propres, principalement pour gérer les données numériques.
Enfin, PL/SQL permet de définir des types complexes basés soit sur des structures issues des tables, soit sur des descriptions propres à l’utilisateur.
Syntaxe
nom-de-variable [CONSTANT]
type [[NOT NULL]:=expression] ;
CONSTANT
La valeur de la variable n’est pas modifiable dans le code de la section BEGIN.
NOT NULL
Empêche l’affectation d’une valeur NULL à la variable, expression doit être fournie.
expression
Valeur initiale affectée à la variable lors de l’exécution du bloc.
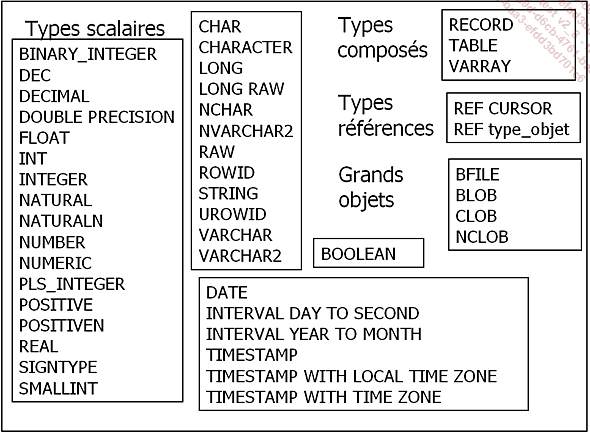
2. Types prédéfinis
a. Types caractères
CHAR[(n)]
Chaîne de caractères de longueur fixe avec n compris entre 1 et 32767. Si aucune taille maximale n’est précisée alors la valeur utilisée par défaut est 1. Il faut également garder présent à l’esprit que la longueur maximale d’une colonne de type CHAR est 2000, et il est donc impossible d’insérer une valeur de plus de 2000...
Structures de contrôle
Les structures de contrôle permettent de choisir la façon dont les différentes instructions vont être exécutées.
Les trois structures de contrôles sont :
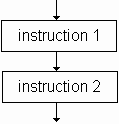
-
la séquence : exécution d’instructions les unes après les autres.
-
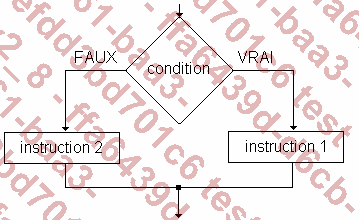
l’alternative : exécution d’instructions en fonction d’une condition.
-
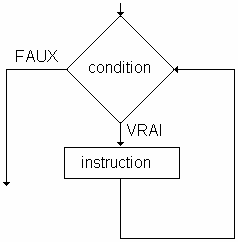
la répétitive : exécution d’instructions plusieurs fois en fonction d’une condition.
1. Traitements conditionnels
 If
IfIl permet l’exécution d’instructions en fonction du résultat d’une condition.
Syntaxe
IF condition1 THEN traitement1;
[ELSIF condition2 THEN traitement2;]
[ELSE
traitement3;]
[END IF;]
Les opérateurs utilisés dans les conditions sont les mêmes que dans SQL : =; <, >, !, >=, <=, IS NULL, IS NOT NULL, BETWEEN, LIKE, AND, OR, etc.
Exemple
Si le client 10 est en cours de traitement, on le met à jour sinon on annule la transaction :
if Vnocli = 10 THEN
UPDATE CLIENTS SET NOM = 'Dupont' where NOCLI = Vnocli ;
COMMIT ;
else
ROLLBACK ;
end if ;
L’instruction CASE permet une exécution conditionnelle comme l’instruction IF. Cependant, cette instruction CASE est particulièrement bien adaptée aux conditions comportant de nombreux choix différents. Elle permet une présentation plus lisible du code, donc moins de risque d’erreur. De plus, l’utilisation du CASE est susceptible d’améliorer les performances au cours de l’exécution.
Syntaxe
[<<étiquette>>]
CASE element_de_selection
WHEN valeur1 THEN instructions1;
WHEN valeur2 THEN instructions2;
...
[ELSE instructions;]
END CASE [étiquette];
[<<étiquette>>]
CASE
WHEN condition1 THEN instructions1;
WHEN condition2 THEN instructions2;
...
[ELSE instructions;]
END CASE [étiquette];
La condition ELSE est optionnelle et elle n’est exécutée...
Utilisation des curseurs
1. Définition
Le curseur est une zone de mémoire de taille fixe, utilisé par le moteur de la base Oracle pour analyser et interpréter tout ordre SQL.
Les statuts d’exécution de l’ordre se trouvent dans le curseur.
Il existe deux types de curseurs :
-
Le curseur implicite : curseur SQL généré et géré par Oracle pour chaque ordre SQL.
-
Le curseur explicite : curseur SQL généré et géré par l’utilisateur pour traiter un ordre SELECT qui ramène plusieurs lignes.
2. Étapes d’utilisation d’un curseur explicite
a. Déclaration
Tout curseur explicite utilisé dans un bloc PL/SQL doit être déclaré dans la section DECLARE du bloc en donnant :
-
son nom,
-
l’ordre SELECT associé.
Syntaxe
CURSOR nom_curseur IS ordre_select;
b. Ouverture
Après avoir déclaré le curseur, on "ouvre" celui-ci pour faire exécuter l’ordre SELECT.
L’ouverture déclenche :
-
l’allocation mémoire du curseur,
-
l’identification du résultat,
-
le positionnement de verrous éventuels (si SELECT ... FOR UPDATE).
L’ouverture du curseur se fait dans la section BEGIN du bloc.
Syntaxe
OPEN nom_curseur;
c. Traitement des lignes
Après l’exécution du SELECT, les lignes ramenées sont traitées une par une, la valeur de chaque colonne du SELECT doit être stockée dans une variable réceptrice.
Syntaxe
FETCH nom_curseur INTO liste_variables;
Le FETCH ramène une seule ligne à la fois ; pour traiter n lignes, il faut une boucle.
d. Fermeture
Après le traitement des lignes pour libérer la place mémoire, on ferme le curseur.
Syntaxe
CLOSE nom_curseur;
e. Curseur FOR
Dans la mesure où l’utilisation principale d’un curseur est le parcours d’un ensemble de lignes ramenées par l’exécution du SELECT associé, il peut être intéressant d’utiliser une syntaxe plus simple pour l’ouverture du curseur et le parcours de la boucle.
Oracle propose une variante de la boucle FOR qui déclare implicitement la variable de parcours, ouvre le curseur, réalise les FETCH successifs et ferme le curseur.
Syntaxe
FOR variable IN cursor LOOP
--instructions ...Gestion des erreurs
De nombreuses erreurs peuvent survenir au cours de l’exécution. Ces erreurs peuvent être d’origine matérielle, dues à une faute de programmation ou de n’importe quelle autre origine. Avec certains langages de programmation, il n’est pas possible de gérer toute sorte d’erreur, comme la division par zéro.
Le langage PL/SQL fournit un mécanisme d’interception des erreurs afin de donner une réponse logicielle à tout type d’erreur. Bien sûr, toutes les erreurs ne pourront être traitées mais il est possible de prévoir une sortie propre du programme quoi qu’il arrive.
Le traitement des erreurs a lieu dans la partie EXCEPTION du bloc PL/SQL. Cette partie est optionnelle et ne doit être définie que si le bloc intercepte des erreurs.
Structure d’un bloc PL/SQL :

La section EXCEPTION permet d’affecter un traitement approprié aux erreurs survenues lors de l’exécution du bloc PL/SQL.
On distingue deux types d’erreurs :
-
les erreurs internes Oracle,
-
les anomalies dues au programme.
Après l’exécution du code correspondant au traitement de l’exception, le bloc en cours d’exécution est terminé, et l’instruction suivante à être exécutée est celle qui suit l’appel à ce bloc PL/SQL dans le bloc maître.
Les avantages de ce mode de gestion des erreurs sont nombreux. Le plus important est représenté par le fait que pour gérer un type d’erreur, le code ne doit être écrit qu’une seule fois.
Dans les langages de programmation qui ne possèdent pas ce mécanisme d’interception des erreurs, l’appel à la fonction traitant l’erreur doit être précisé à chaque fois que l’erreur peut se produire.
Schéma résumant le principal avantage d’un mécanisme d’interception des erreurs :

Règles à respecter
-
Définir et donner un nom à chaque erreur (différent pour les erreurs utilisateur et les erreurs Oracle).
-
Associer une entrée dans la section EXCEPTION pour chaque nom d’erreur défini dans la partie DECLARE.
-
Définir le traitement à effectuer dans la partie EXCEPTION.
La levée...
Exemple récapitulatif
L’exemple suivant montre les syntaxes utilisées pour la gestion des variables, des curseurs et les structures de contrôle dans un programme complet.
Ce programme est exécuté via SQL*Plus.
1. Énoncé du traitement
On veut pouvoir mettre à jour la quantité en stock de la table ARTICLES (REFART, DESIGNATION, PRIXHT, QTESTK) à partir des commandes en cours (ETATCDE = ’EC’) stockées dans les tables COMMANDES (NOCDE, NOCLI, DATCDE, ETATCDE) et LIGNESCDE (NOCDE, NOLIG, REFART, QTECDE).
Le traitement doit mettre à jour la colonne QTESTK de ARTICLES en otant les QTECDE de LIGNESCDE pour l’article. Il doit également y avoir mise à jour de ETATCDE à ’LI’ si toutes les quantités peuvent être livrées pour la commande (QTESTK > 0 après décrémentation).
Dans le cas où la quantité en stock de l’article devient négative, les mises à jour pour cette commande sont annulées.
Une table témoin est mise à jour pour chaque article à problème (non livrable) et pour chaque commande livrée entièrement.
2. Exemple
Script majliv.sql.
-- Livraison des commandes et mise à jour des stocks
-- Création de la table TEMOIN
create table TEMOIN(nocde number(6), texte char(60));
-- Bloc PL/SQL de mise à jour
DECLARE
cursor ccde is select c.nocde, refart, qtecde
from ligcdes l,commandes c
where c.nocde=l.nocde
and c.etatcde='EC'
order by c.nocde;
vcde ccde%rowtype;
vqtestk articles.qtestk%type;
vnvqte vqtestk%type;
vtexte temoin.texte%type;
verr...
