
Centralisation des journaux d’activité
Objectifs du chapitre et prérequis
Lors des précédents chapitres, le lecteur a appris à consulter les journaux d’activité des containers. Il a également appris qu’un container avait une durée de vie particulièrement courte.
En réalité, un simple crash aboutira à la création d’un nouveau container et l’impossibilité de consulter le journal d’activité qui aurait pu expliquer ce crash. Pour parer à cette éventualité, Kubernetes offre la possibilité de centraliser les journaux d’activité.
Les différentes solutions natives aux services managés seront étudiées :
-
Google Stackdriver
-
Azure Monitor
-
Amazon Cloudwatch
Dans le cas de Google et Azure, ces solutions sont préconfigurées à la création du cluster. Dans le cas d’Amazon, une proposition de solution sera étudiée avec le service Cloudwatch.
Dans le cas d’un cluster hébergé (on premise), le lecteur se verra présenter deux solutions :
-
Loki (développé par la société du logiciel Grafana)
-
Elasticsearch
Les deux solutions autour de Loki et Elasticsearch ont chacune leurs inconvénients et avantages. Elles seront évoquées un peu plus loin dans la section dédiée à la mise en place...
Principe de la centralisation des journaux
1. Architecture
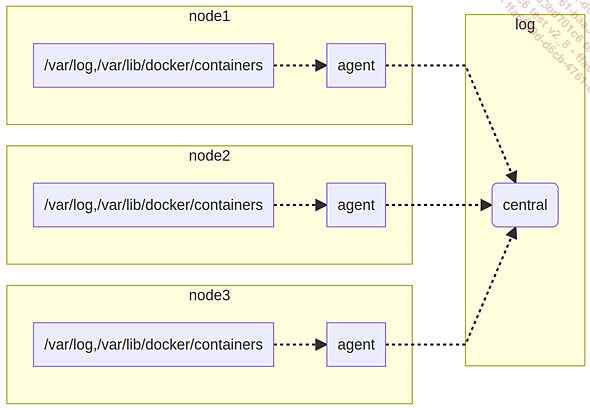
Principe de fonctionnement de la centralisation de l’activité des différents nœuds
Toutes les solutions qui vont suivre s’appuient sur le même mécanisme :
-
Collecte des journaux d’activités sur chaque nœud à l’aide d’un agent.
-
Envoi de ces journaux vers un point de stockage centralisé.
Certains clusters sont préconfigurés (c’est généralement le cas des services managés) quand d’autres sont à déployer (c’est le cas d’Amazon ou des clusters installés manuellement).
2. Caractéristiques de l’agent déployé
L’agent en charge de ce travail s’appuie sur un objet DaemonSet. Chaque nœud lance un pod ayant accès aux répertoires de la machine hôte :
-
Le répertoire /var/lib/docker/containers pour accéder aux logs des containers.
-
Le répertoire /var/log pour accéder aux logs de la machine.
Le pod garde des fichiers de traces afin de savoir où en est le travail de collecte des logs.
Dans le cas de Fluentd, ces fichiers se présentent sous la forme de fichiers .pos stockés sur la machine principale dans le répertoire /var/log. Ces fichiers de positions sont au format texte et contiennent une ligne par journal où figurent les champs suivants...
Centralisation dans le cloud
1. Centralisation à l’aide d’un service managé
Les fournisseurs de cloud proposent des outils pour centraliser les journaux d’activité. Certains de ces services sont définis nativement à la création du cluster (Google ou Azure) quand d’autres réclament une configuration spécifique (Amazon).
Il s’agit de la solution à privilégier dans un premier temps (surtout lorsque l’intégration est déjà faite par défaut). Attention toutefois à prendre en compte les coûts que peuvent engendrer ce type de solution, d’autant que ces outils n’ont pas toujours la convivialité ou la puissance d’une solution basée sur Elasticsearch et Kibana.
2. Google Stackdriver
a. Présentation de Stackdriver
La centralisation des journaux d’activité chez Google se fait à l’aide de l’outil Stackdriver. Par défaut, l’envoi des logs vers ce service est réalisé à la création du cluster.
La centralisation des logs nécessite que l’API Stackdriver soit active. Visitez la page Stackdriver Logging API dans la console Google Cloud.
b. Pod Fluentbit (cluster GKE)
L’envoi des logs d’un cluster GKE s’appuie sur le logiciel Fluentbit déployé à l’aide d’un DaemonSet. Les pods associés sont marqués à l’aide du label app=fluent-bit-gke et sont lancés dans l’espace de noms kube-system.
Ci-dessous la commande permettant de consulter ces pods :
$ kubectl -n kube-system get pods -l k8s-app=fluentbit-gke Ci-dessous un exemple de résultat sur un cluster composé de trois nœuds :
NAME READY STATUS RESTARTS AGE
fluentbit-gke-d8bdg 2/2 Running 0 6d21h
fluentbit-gke-pwrpw 2/2 Running 0 6d21h
fluentbit-gke-wgj98 2/2 Running 0 6d21h...Centralisation des journaux avec Loki
1. Présentation de Loki
a. Origine de Loki
Loki est un outil développé par la société à l’origine de Grafana. Le but de Loki est de proposer un outil semblable à Prometheus, mais à destination des logs.
Tout comme Prometheus, Loki récupère et stocke les labels des pods. Il est également très léger et consomme très peu de ressources (surtout comparé à une solution basée sur Elasticsearch).
Le produit a néanmoins une contrainte : il n’indexe pas le contenu des logs. Il n’y a donc pas possibilité de faire de la recherche textuelle directe.
b. Loki vs Elasticsearch
Ce qui peut paraître un désavantage en fait également sa force. Du fait qu’il n’y a pas de travail d’indexation, le processus de stockage des journaux est très peu gourmand.
Là où un processus Loki consommera moins d’un Go de mémoire, les processus Elasticsearch peuvent faire facilement monter cette valeur à plus de 10 Go de mémoire.
Malgré tout, il ne s’agit pas de savoir si Loki doit remplacer Elasticsearch, mais plutôt d’être conscient de ces avantages et inconvénients. Ne pas oublier par exemple que Loki ne fait pas d’indexation du texte. Pour ce type de besoin, Elasticsearch reste indispensable.
c. Conseil d’utilisation
Du fait de la consommation des labels des pods, la recherche pourra se faire à l’aide de ces derniers....
Centralisation des journaux avec Elasticsearch
1. Avertissements et limitations
Cette section n’a pas pour vocation de comprendre le fonctionnement global d’Elasticsearch. Elle ne doit être vue que comme une aide à sa mise en œuvre dans Kubernetes.
Vous êtes invité à vous tourner vers la documentation officielle d’Elasticsearch pour respecter les bonnes pratiques.
2. À propos d’Elasticsearch
Elasticsearch est un serveur s’appuyant sur Lucene. Ce type de base de données permet de stocker des éléments sous une forme déstructurée. Dans la mise en place de Kubernetes, il peut être utilisé pour centraliser les journaux d’activité des containers.
Pour la suite, la centralisation des journaux se fera à l’aide d’un agent Filebeat déployé sur chaque nœud du cluster (d’autres solutions sont possibles avec fluent-bit ou fluentd, par exemple). Le déploiement se fait naturellement avec un objet DaemonSet.
Le déploiement d’Elasticsearch réclame une certaine quantité de ressources. Il est déconseillé de le déployer sur un cluster constitué de nœuds ne disposant pas au moins de 2 CPU et 4 Go de mémoire.
3. Déploiement des briques Elasticsearch
a. Installation d’Elasticsearch
Dans le cas où vous disposeriez déjà d’un cluster Elasticsearch externe à Kubernetes, vous pouvez passer à la section suivante.
L’installation d’Elasticsearch se fera à l’aide du chart Helm elastic/elasticsearch. Avant l’installation du chart, ajoutez la source des paquets à l’aide de la commande suivante :
$ helm install elasticsearch elastic/elasticsearch Le chart utilisé déploie des pods sans limitations CPU ou mémoire.
Afin de limiter la consommation, utilisez les déclarations suivantes :
resources:
limits:
cpu: "1"
memory:...Gestion d’Elasticsearch
1. Accès à l’interface Cerebro
Les pods associés à Cerebro portent le label app=cerebro.
Consultez la liste des pods associés à ce label dans l’espace de noms elasticsearch :
$ kubectl get pods Ci-dessous un exemple de résultat :
NAME READY STATUS RESTARTS AGE
cerebro-64bd586f6-5fjt6 1/1 Running 0 7m37s L’application Cerebro pour fonctionner fait appel au port 9000. Ouvrez ce port à l’aide de l’instruction port-forward sur le pod de Cerebro :
$ kubectl -n elasticsearch port-forward deploy/cerebro 9000 Entrez ensuite l’adresse http://localhost:9000 dans un navigateur.
Page d’accueil de Cerebro
Saisissez l’adresse d’Elasticsearch (http://elasticsearch-master:9200) afin d’arriver sur l’interface d’administration des index.
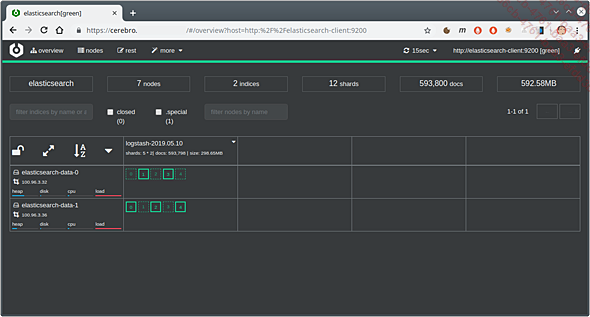
Exemple d’affichage avec Cerebro d’un cluster Elasticsearch déployé dans Kubernetes
2. Utilisation de Kibana
a. Accéder à l’interface de Kibana
Afin de se connecter à Kibana, lancez la commande suivante :
$ kubectl -n elasticsearch port-forward deploy/kibana-kibana 5601 Entrez ensuite l’adresse http://localhost:5601 dans...
