
Surveillance à l’aide de Prometheus
Objectifs du chapitre et prérequis
Vous avez maintenant une bonne vision d’ensemble des briques présentes dans un cluster Kubernetes. La question du cycle de vie des pods a été abordée ainsi que les mécanismes permettant de maintenir en conditions opérationnelles les applications déployées dans Kubernetes.
En revanche, la question de la surveillance de ces briques n’a pas du tout été abordée. Ainsi, vous n’avez pas encore la capacité de connaître l’état d’un service ou la consommation CPU ou la mémoire d’un ensemble de pods.
Autre difficulté : l’aspect hautement dynamique des éléments dans un cluster Kubernetes :
-
Les pods changent de nom.
-
Les noms des volumes ne sont pas prédéterminés à l’avance.
-
Les nœuds changent de nom.
-
Les environnements peuvent disparaître aussi vite qu’ils sont apparus.
Dans ce qui va suivre, vous allez découvrir l’utilisation de Prometheus.
Ce chapitre est une introduction et non un guide complet de mise en place. Pour aller plus loin, vous pourrez vous tourner vers les différentes ressources indiquées dans ce chapitre ou vers la recherche d’informations sur Internet. N’hésitez pas non plus à consulter le livre sur Prometheus et Grafana du même auteur aux Éditions...
Mise en place de Prometheus
1. À propos de Prometheus
Prometheus est un outil de surveillance construit autour d’une base de données de séries temporelles. L’alimentation de cette base de données est réalisée par l’outil lui-même en allant scruter à intervalle régulier les différents points d’acquisition de la donnée. La communication s’appuie sur le protocole HTTP et les points de collecte sont appelés des exporteurs.
Ces exporteurs sont de plus en plus intégrés directement dans les applications du marché. Lorsque ce n’est pas le cas (pour les bases de données, par exemple), un process doit être lancé afin de permettre de faire le pont entre Prometheus et le produit à surveiller.
Dans le contexte des containers, Prometheus s’intègre particulièrement bien pour plusieurs raisons :
-
Rapide et léger : Prometheus est particulièrement optimisé.
-
Dynamique : Prometheus détecte en continu les créations et suppressions de services et/ou pods.
Autre point important : la plupart des briques Kubernetes disposent nativement d’un point de collecte Prometheus. L’intégration en est donc fortement facilitée.
Le projet est soutenu par la fondation CNCF (qui s’occupe également de Kubernetes).
Consultez l’adresse suivante pour en apprendre un peu plus sur le moteur Prometheus : https://prometheus.io
2. Fonctionnement de Prometheus
a. Architecture de Prometheus
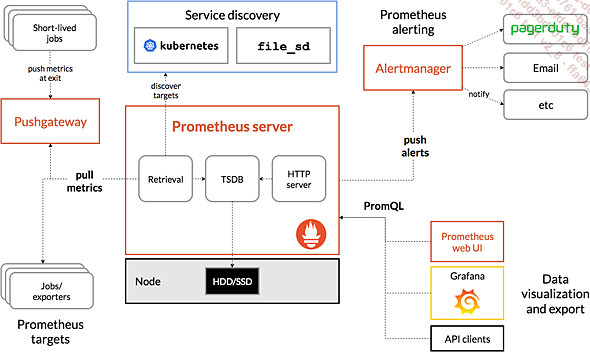
Schéma d’architecture des principales briques de Prometheus (extrait du site https://prometheus.io)
b. Le moteur Prometheus
Le serveur Prometheus prend en charge plusieurs opérations :
-
Scruter l’état des éléments à surveiller à l’aide d’exporteurs.
-
Stocker les métriques dans un moteur de base de données de série temporelle (TSDB pour Time Series Database).
-
Exposer ces métriques à travers une interface REST.
Le moteur Prometheus supporte des mécanismes de découverte automatique de services (Azure, EC2, Consul, Kubernetes, etc.). Dans le cas de Kubernetes, le moteur est en mesure de détecter l’ajout ou le retrait automatique des pods.
c. Les exporteurs Prometheus
Autre brique particulièrement...
Utilisation de Prometheus
1. Fonctionnement des métriques
a. Consultation des métriques de Prometheus
Le moteur Prometheus dispose d’un point de collecte de métriques sur le port 9090 (port d’écoute par défaut) dans le contexte /metrics.
Afin d’accéder au port 9090 du serveur Prometheus en local, lancez la commande suivante :
$ kubectl -n monitoring port-forward svc/prometheus-operated 9090 Entrez ensuite l’adresse http://localhost:9090/metrics dans un navigateur.
Sous Google Chrome, installez l’extension « Prometheus Formatter » afin de disposer d’un formatage des données des exporteurs Prometheus.
Métriques internes renvoyées par le moteur Prometheus formatées à l’aide de l’extension « Prometheus Formatter » sous Chrome
b. Présentation de l’interface de Prometheus
En plus des métriques, Prometheus offre - sur le même port d’écoute - une console permettant d’interroger le moteur.
Gardez le port 9090 ouvert précédemment et consultez l’adresse suivante dans un navigateur : http://localhost:9090
Page d’accueil de Prometheus
L’interface principale permet d’interroger directement les métriques de Prometheus.
Entrez la valeur node:node_cpu_utilisation:avg1m dans l’interface et cliquez ensuite sur Execute puis sur Graph.
L’interface renverra alors l’activité moyenne sur une minute des CPU de chaque nœud du cluster.
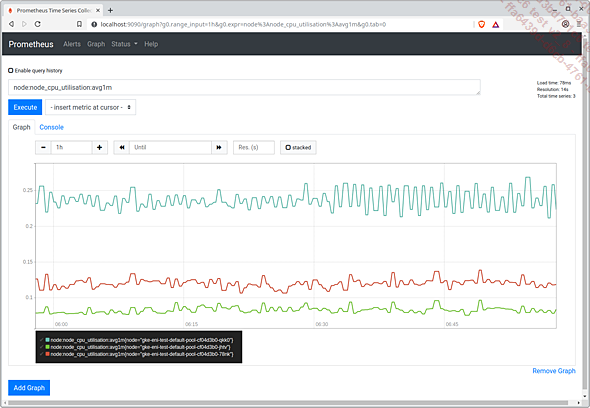
Évolution de l’activité CPU des nœuds du cluster minute par minute
c. Métriques de Kubernetes
Le moteur Prometheus est en mesure de détecter la création ou la suppression de nouveaux pods. Leur seule présence (du fait de la présence de l’exporteur prometheus-kube-metrics) permet de récupérer de nombreuses métriques système :
-
Consommation de la CPU et mémoire.
-
Activité des entrées/sorties (réseau et disque).
-
État des espaces disque.
En plus de ces éléments de base, il est possible de scruter des métriques personnalisées mises à disposition au niveau d’un container à l’aide d’objets de type ServiceMonitor.
d. Déclaration des points de collecte...
Tableaux de bord Grafana
1. Présentation de Grafana
Grafana est un logiciel permettant de faire de la visualisation de données. Ce logiciel accepte de nombreuses sources de données (datasources) :
-
Les bases de données temporelles (InfluxDB, Graphite, Prometheus).
-
Les moteurs de bases de données NoSQL (Elasticsearch).
-
Les moteurs de bases de données classiques SQL (Postgres, MySQL).
Ces sources de données peuvent être ensuite mises en page dans des tableaux de bord (dashboards).
2. Configuration de Grafana
a. Branchement au moteur Prometheus
Grafana, pour se brancher sur le moteur Prometheus, s’appuie sur un objet datasource. Ce dernier est configuré à l’aide d’un objet configmap portant le label grafana_datasource=1.
Récupérez les objets configmap portant ce label dans l’espace de noms monitoring :
$ kubectl -n monitoring get configmap -l grafana_datasource=1 Ci-dessous le champ data de l’objet présent par défaut à l’installation du chart de l’opérateur Prometheus :
data:
datasource.yaml: |-
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
url: http://prometheus-prometheus-oper-prometheus:9090/
access: proxy
isDefault: true...Suppression du chart de Prometheus
En fin d’exercice, la suppression de Prometheus se fait en deux étapes :
-
Suppression du chart Helm.
-
Suppression des ressources personnalisées (CRD).
Supprimez le chart à l’aide de la commande suivante :
$ helm delete prometheus Supprimez ensuite les ressources CRD à l’aide de l’instruction suivante :
$ kubectl delete crd alertmanagerconfigs.monitoring.coreos.com \
alertmanagers.monitoring.coreos.com \
podmonitors.monitoring.coreos.com \
probes.monitoring.coreos.com \
prometheuses.monitoring.coreos.com \
prometheusrules.monitoring.coreos.com \
servicemonitors.monitoring.coreos.com \ ...