
Restriction et délégation d’accès
Objectifs du chapitre et prérequis
Ce chapitre présente comment mettre en place une stratégie de limitation de la consommation de ressources sur un cluster. Cette stratégie s’appuie sur plusieurs mécanismes :
-
Utilisation d’espaces de noms.
-
Définition de limites sur ces espaces de noms.
-
Gestion des droits utilisateurs sur un cluster (avec cloisonnement par espace de noms).
-
Mise en place d’un mécanisme d’authentification externe (basé sur le protocole OAuth2).
Pour chacun de ces différents problèmes, des solutions seront exposées.
Une dernière partie sera consacrée à la mise en place de comptes d’accès techniques. Ils permettent la mise à jour ou le lancement de travaux depuis des outils externes (CI/CD, ordonnanceurs externes, etc.).
Mise en place de quotas
1. Origine du besoin
Jusqu’à maintenant, les ressources créées n’avaient pas forcément d’espaces de noms ou de restrictions de consommation. Dans le cas d’un cluster utilisé par plusieurs équipes, une bonne pratique est de séparer les différentes applications ou environnements applicatifs à l’aide d’espaces de noms et d’y rattacher des garde-fous.
Dans Kubernetes, ces garde-fous prennent la forme de quotas et peuvent se définir à l’aide de deux types de limitations :
-
Des limitations individuelles sur les containers/pods (LimitRange).
-
Des limitations de consommation de ressources cumulées sur un espace de noms (ResourceQuota).
Ci-dessous quelques exemples de définitions de limitations :
-
Limitation de consommation CPU et/ou mémoire par pod ou global.
-
Limitation du nombre d’occurrences d’objets (pods, déploiement, service).
-
Règles entre la consommation minimum et maximum d’une ressource.
À noter que la définition de quotas de ressources (ResourceQuota) sur un espace de noms forcera à définir des limitations au niveau des containers. Un container/pod sans ces limitations ne pourra pas y être déployé.
2. Quotas par défaut sur un espace de noms
a. Création d’un espace de noms
Pour la suite des opérations, l’espace de noms test sera utilisé. La première opération va donc consister à le créer :
$ kubectl create ns test Les objets LimitRange et ResourceQuota sont tous les deux rattachés à un espace de noms. Leur rattachement peut se faire de plusieurs manières :
-
Soit au niveau du champ metadata --> namespace.
-
Soit en spécifiant l’option -n suivie par l’espace de noms au lancement de kubectl.
-
Soit en faisant appel à la commande kubens.
Pour la suite des exercices, basculez sur l’espace de noms test :
$ kubens test b. Structure d’un objet LimitRange
Un objet LimitRange est un premier type de quota. Si un pod ou un container est créé sans limitation, cet objet viendra définir des valeurs par défaut.
Ces limitations sont les mêmes que celles abordées dans le chapitre Cycle de vie d’un container dans Kubernetes, à...
Authentification et autorisation
1. Origine du besoin
La section précédente a été consacrée à la mise en place de restrictions sur les accès au niveau des espaces de noms. Toutefois, les accès ont tous été réalisés avec le même identifiant.
Le fichier Kubeconfig devient donc une ressource critique comme le serait un mot de passe root ou une clé privée SSH.
Si dans une équipe restreinte ce type de problématique reste acceptable, dans une organisation plus imposante, cette situation peut poser problème.
Les utilisateurs peuvent être authentifiés à l’aide de plusieurs mécanismes :
-
en autorisant les accès anonymes,
-
par certificats clients x509,
-
par fichiers statiques de définition d’utilisateurs,
-
par utilisateurs authentifiés à l’aide d’OAuth2,
-
par proxy d’authentification.
Certains de ces accès s’appuient sur la configuration du serveur d’API de Kubernetes via l’utilisation d’options de démarrage ou sur l’émission de certificats générés à l’aide de la clé privée du cluster (Private Key Infrastructure).
Par la suite, vous aborderez les mécanismes suivants :
-
Mise en place d’accès anonymes.
-
Authentification par certificat.
-
Authentification par mécanisme externe (basé sur OAuth2).
Enfin, le lecteur abordera l’utilisation de comptes de service (objet ServiceAccount). Ce mécanisme est à utiliser dans le cas d’appels externes comme par exemple lors de l’utilisation d’automates.
2. Prérequis
Les exercices qui suivent s’appuieront sur la modification des options de démarrage de l’API de Kubernetes ou sur l’émission de certificats basés sur la clé du cluster. Naturellement, cet exercice ne pourra pas se faire sur un cluster managé du fait de l’impossibilité d’accéder aux certificats internes du cluster ou aux options de démarrage de l’API.
Il est donc indispensable que le cluster ait été créé par vous (à l’aide de Kubespray ou k3s, mais également avec d’autres méthodes comme par exemple Kubeadm, Kops, Minikube, etc.)...
Mécanismes d’authentification externes
1. Présentation du mécanisme
Dans Kubernetes, il n’existe pas de type pour représenter un utilisateur : ils sont directement référencés sous la forme d’un identifiant (clement, admin@my-company.com) ou d’un groupe (administrator, intranet, etc.).
Dans la suite du chapitre, l’accès à l’aide d’identifiants OAuth2 sera abordé.
L’accès par identifiants OAuth2 est assez similaire à ce qui a été fait dans le chapitre Sécurisation : accès aux applications. L’exercice se fera avec les API de Google, mais les instructions sont tout à fait transposables avec celle de GitHub ou de n’importe quel fournisseur d’identifiants OAuth2.
2. Communication entre le fournisseur OAuth2 et le cluster
L’authentification entre le cluster et le fournisseur d’identifiants s’appuie sur le protocole OpenID Connect (une extension répandue du protocole OAuth2 supportée par Google ou Azure).
Le principal ajout est la présence d’un champ contenant un jeton d’identification de type JWT (JSON Web Token). Ce jeton sert à l’authentification de l’utilisateur et peut également contenir des champs supplémentaires comme par exemple l’e-mail de l’utilisateur. Il est également signé par le fournisseur d’identité.
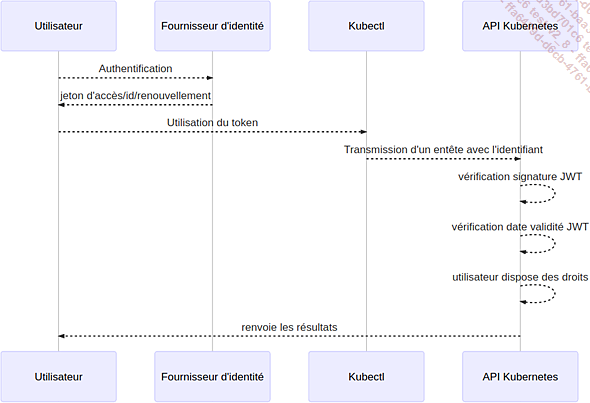
Diagramme de la communication entre le cluster Kubernetes et le fournisseur OAuth2
3. Création des identifiants
Première étape : créer des identifiants clients pour OAuth2. Cette opération se fait depuis la console de Google (ou de tout autre fournisseur d’identité).
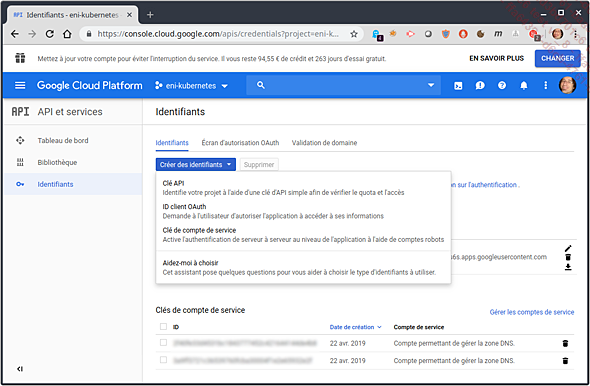
Création d’identifiant ID client OAuth
Dans l’écran suivant, choisissez le type d’application Autre.
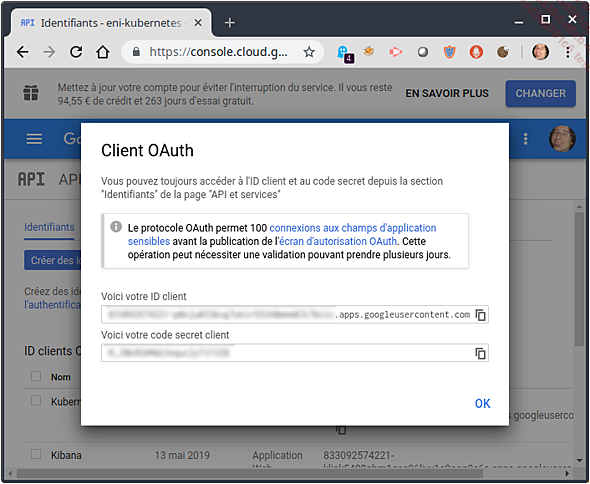
Récupération des identifiants suite à la création d’identifiant ID client OAuth
Dans le dernier écran, récupérez l’ID et le secret client pour une utilisation ultérieure.
4. Modification des options de démarrage (Minikube)
La modification des options de démarrage du cluster reprend la même procédure que celle d’activation des accès anonymes.
Ouvrez une connexion...
Mise en place de comptes de service
1. Contexte
Un bon moyen d’interagir avec un cluster Kubernetes est de passer par un compte de service. Ce besoin se justifie généralement lors de la mise en place d’automates (déploiement continu, compilation, audit de sécurité, surveillance, etc.).
Toutefois, l’utilisation de ce type d’accès doit faire l’objet d’une grande attention. Le jeton d’authentification donne le droit de réaliser toutes les opérations permises de l’utilisateur technique.
Par la suite, le lecteur procédera à la création d’un compte de service accessible depuis l’extérieur du cluster.
2. Création du compte de service
La création d’un compte de service se fait à l’aide d’un objet de type ServiceAccount.
Ci-dessous les champs nécessaires :
-
Le champ apiVersion (v1) et kind (ServiceAccount).
-
Le champ metadata avec deux sous-champs :
-
Le champ name positionné à la valeur cicd.
-
Le champ namespace positionné à la valeur default.
Ci-dessous la déclaration correspondante :
apiVersion: v1
kind: ServiceAccount
metadata:
name: cicd
namespace: default Sauvegardez cette définition dans le fichier cicd-account.yaml et appliquez sa déclaration auprès du cluster Kubernetes :
$ kubectl apply -f cicd-account.yaml Une méthode alternative est de passer par la commande kubectl create suivie des options suivantes :
-
Le type d’objet à créer (serviceaccount).
-
L’espace de noms à utiliser (--namespacedefault).
-
Le nom de l’objet à créer : cicd.
Ci-dessous la commande correspondante :
$ kubectl create serviceaccount --namespace default cicd Le choix de l’une ou l’autre des méthodes revient au lecteur. Néanmoins, la première méthode est préférée puisqu’il est plus facile de stocker la déclaration du compte dans un dépôt Git.
3. Attribution des droits d’administrateur au compte de service
Le compte doit maintenant être rattaché au rôle cluster-admin. Ce rattachement va se faire à l’aide d’un objet ClusterRoleBinding. Cet objet est structuré de la manière suivante :...
