
Le clustering avec Windows Server
Introduction au clustering
1. Généralités
Le clustering consiste à réunir plusieurs machines en une seule entité logique, et il peut avoir deux buts, prévenir les défaillances matérielles ou augmenter les ressources à disposition, ou les deux en même temps.
Nous avons dans cet ouvrage déjà abordé le cluster DHCP, qui permet soit d’avoir un serveur en attente au cas où le premier serait en panne, soit de répartir la charge de travail entre les deux serveurs.
Dans ce chapitre, nous allons étudier le clustering de serveurs, avec plusieurs serveurs qui mettent en œuvre un service comme Hyper-V ou SQL ou serveur de fichiers, réunis en une seule entité.
Dans un cluster chaque serveur est appelé un node et Windows Server peut gérer des clusters allant de 2 à 64 nodes. Ces nodes peuvent être des machines physiques ou virtuelles. Il est possible de faire des clusters dans un domaine Active Directory, dans plusieurs domaines différents ou même dans un Workgroup sans domaine.
Typiquement, les serveurs d’un cluster, les nodes, vont partager un stockage commun via le réseau. Ce stockage peut prendre plusieurs formes, comme des boîtiers JBOD, du stockage iSCSI, de simples partages dans un pool de stockage, peu importe, l’important étant que tous les nodes puissent avoir...
Mise en place du lab
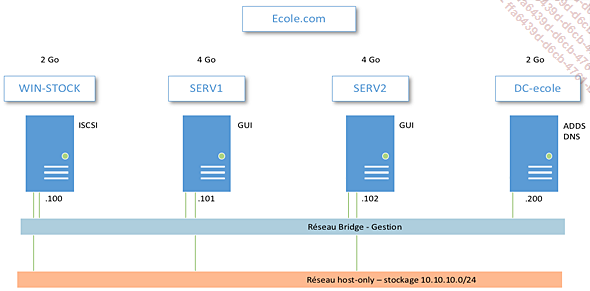
Dans ce lab, nous aurons quatre serveurs, dont un contrôleur de domaine, deux serveurs sur lesquels nous pourrons installer différents rôles, et un serveur de stockage. Tous les serveurs sont membres du domaine, ce qui nous facilitera l’authentification et la résolution DNS. Tous les serveurs ont une interface graphique.
Les serveurs du cluster ainsi que le serveur de stockage ont deux cartes réseau. La première est dans un réseau bridgé ou externe de votre hyperviseur, qui servira de réseau de gestion et de communication du cluster, et qui donc aura accès au réseau réel. L’adressage IP des cartes réseau dans le réseau de gestion est à adapter à l’adressage IP de votre réseau réel.
L’autre carte réseau est dans un réseau host-only de votre hyperviseur, sans accès au réseau réel, et servira au cluster à accéder à ce stockage. Le contrôleur de domaine n’a pas accès à ce réseau.
Le lab va être amené à évoluer au cours de ce chapitre, mais nous avons là une base solide pour découvrir le clustering dans Windows Server. N’hésitez pas à prendre des snapshots de votre infrastructure régulièrement.
Cluster de basculement
1. Configuration du stockage
La première chose à mettre en œuvre dans un cluster de basculement est le stockage. Nous allons créer un stockage iSCSI dans le serveur WIN-STOCK du lab. Nous avons aussi besoin de créer un témoin pour le quorum du cluster.
Nous avons déjà vu comment paramétrer l’iSCSI dans le chapitre Le stockage de ce livre, mais nous allons revoir ce procédé en ajoutant quelques notions supplémentaires ainsi que des commandes PowerShell.
a. Pré-configuration des initiateurs iSCSI
Nous allons commencer par activer les initiateurs iSCSI sur les deux serveurs du cluster, ce qui permettra de mettre en cache leur IQN et de ne pas avoir à les remplir à la main lors de la création de la cible sur le serveur de stockage.
Pour activer les initiateurs, démarrez et configurez le service iSCSI sur les deux machines. Faites-le avec PowerShell depuis le contrôleur de domaine :

Vérifiez les initiateurs avec PowerShell :
Invoke-Command serv1,serv2 { Get-InitiatorPort } Ce qui donne un résultat où l’on peut voir que les IQN des initiateurs ont été créés :

Dans la commande suivante, indiquez le serveur de stockage aux initiateurs, ce qui leur permettra de dialoguer avec lui. Cela mettra en cache les IQN des initiateurs dans le serveur cible, et vous n’aurez pas à les remplir à la main. L’IP est celle du serveur WIN-STOCK dans le réseau dévolu au stockage.
Invoke-Command serv1,serv2 { New-IscsiTargetPortal
-TargetPortalAddress 10.10.10.100 } b. Configuration du serveur de stockage
Ajoutez un disque de 200 Go au serveur de stockage et formatez-le en ReFS.
Ajoutez le service de rôle iSCSI Targer Server dans le serveur.

Lancez la création du disque virtuel iSCSI dans le nouveau volume.

Donnez-lui un nom, réglez sa taille à 150 Go, avec allocation dynamique et cliquez sur Next.
Créez la cible iSCSI et donnez-lui un nom.
Dans la page suivante, cliquez sur Add pour paramétrer l’accès des initiateurs. Les initiateurs sont déjà ajoutés en cache.

Ajoutez les deux IQN des deux serveurs.
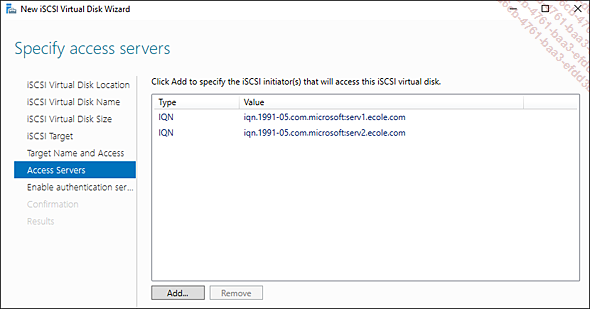
Ignorez les autres réglages et cliquez...
Serveur de fichiers SOFS
1. Introduction au SOFS
Un serveur de fichiers SOFS (Scale Out File Server), aussi appelé « serveur de fichiers avec montée en puissance parallèle », est un serveur où tous les nodes du cluster sont actifs en même temps.
En effet, dans le cluster de serveur de fichiers que nous avons fait dans la section précédente de ce chapitre, un seul node était actif et l’autre était en attente, en cas de panne et de basculement. Seul le node actif était connecté aux partages.
Dans un serveur SOFS, tous les nodes sont connectés aux partages en même temps et tous participent à l’acheminement des données vers les clients, ce qui permet une bande passante bien supérieure. Ce mécanisme utilise une fonctionnalité de SMB 3 qui est le SMB multi canal.
Un autre bénéfice des serveurs SOFS est que nous pouvons rajouter des serveurs au cluster facilement, ce qui permet d’augmenter encore la bande passante et assure une meilleure tolérance aux pannes.
Il sera aussi possible d’éteindre un node pour maintenance sans avoir à se soucier du basculement.
Pour être capable de connecter plusieurs nodes a un partage, le système utilise des CSV (Cluster Shared Volumes ou volumes partagés). Ces volumes n’utilisent pas NTFS ou ReFS, qui ne permettent pas de monter un volume dans plusieurs endroits, mais un système de fichiers spécialisé, le CSVFS. Ceci est fait en ajoutant une couche logicielle entre les volumes NTFS ou ReFS et le cluster.
Cette couche logicielle sépare les métadonnées des données utilisateurs, pour pouvoir gérer ces métadonnées avec plusieurs nodes. En effet, NTFS et ReFS permettent...
Cluster Hyper-V
Il est temps maintenant dans notre apprentissage de faire un cluster de serveurs Hyper-V. Pour cela, nous allons avoir besoin que les deux machines SERV1 et SERV2 aient le rôle Hyper-V installé. Ce n’est possible que si la virtualisation imbriquée est activée dans les machines virtuelles dans votre hyperviseur.
Attention, l’installation d’Hyper-V va installer un nouvel adaptateur de carte réseau dans chacun des serveurs. Pensez à vérifier sa configuration avant d’aller plus loin.
1. Installation du cluster Hyper-V
a. Préparation du cluster
Après avoir activé la virtualisation imbriquée dans les processeurs des machines, installez Hyper-V dans SERV1 et SERV2.
Supprimez le rôle de cluster SOFS et refaites un CSV depuis le stockage existant.
Après avoir supprimé le rôle SOFS du cluster, allez sur le disque et ajoutez-le aux CSV du cluster.

Depuis l’explorateur d’un des serveurs, allez dans le CSV et créez un dossier pour placer les machines virtuelles.

b. Créer une première VM
Dans le gestionnaire de cluster, faites un clic droit sur Roles, sélectionnez Virtual Machines puis New Virtual Machine.
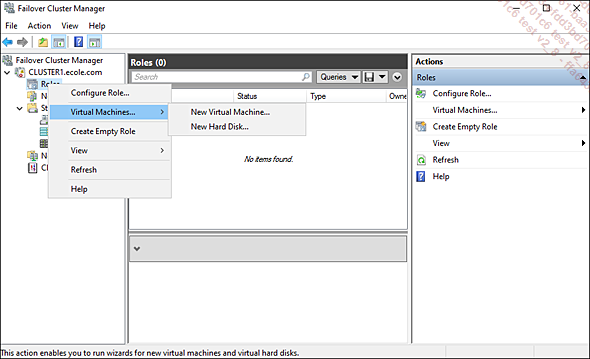
Vous devez ensuite décider quel serveur hébergera la machine virtuelle.
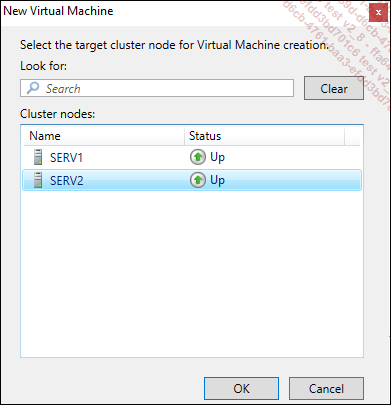
L’assistant pour créer une machine virtuelle se lance. Donnez un nom à la machine et placez-la dans le dossier créé dans le volume CSV.

Faites une machine de génération 2 avec 1024 Mo de mémoire et allocation dynamique, connectez-la au switch externe créé à l’installation d’Hyper-V.
Puis dans les réglages du disque VHDX, vérifiez que le système a bien placé le disque dans le volume partagé.

Dites que vous voulez installer le système d’opération plus tard et validez jusqu’à la création de la machine virtuelle.
Vous allez avoir un message de récapitulation avec la possibilité d’afficher...
Espaces de stockage direct
1. Introduction
a. Concepts de base
Les espaces de stockage direct, aussi appelé « storage space direct » ou « S2D » par Microsoft, sont une technologie qui permet d’agréger le stockage local des serveurs qui composent un cluster, dans un pool de stockage. Cela permet de réaliser ce que l’on appelle une infrastructure hyperconvergée.
Cela permet de combiner les types de disque SSD et HD, en SATA, NVME ou SAS, de disposer d’un cache d’écriture, des tiers de stockage et de la résilience de type miroir ou parité des pools de stockage. Des volumes NTFS ou ReFS peuvent être utilisés.
Il existe aussi un type de déploiement pour les espaces de stockage directs dits « convergés », où il y a deux clusters : un cluster SOFS pour le stockage et un cluster pour les ressources de calculs. Dans ce livre, nous ne parlerons que des architectures hyperconvergées.
Les espaces de stockage direct utilisent plusieurs technologies de Windows Server simultanément, cluster de basculement, les volumes partagés CSV, les pools de stockage et ajoutent une fonctionnalité appelée le bus de stockage virtuel.
Le bus de stockage virtuel permet aux serveurs inclus dans le cluster de voir les disques attachés aux autres serveurs. La communication entre les serveurs et les différents disques passe simplement par les connexions Ethernet des serveurs.
Les espaces de stockage direct nécessitent Windows Server 2022 Datacenter Edition et jusqu’à 16 serveurs peuvent être réunis dans un espace de stockage direct hyperconvergé.
b. Notions sur l’hyperconvergence
La notion essentielle sur l’hyperconvergence est que le stockage et la puissance de calcul sont dans la même machine. Il en découle de nombreux avantages. Les infrastructures hyperconvergées (HCI), par rapport aux infrastructures traditionnelles avec des baies de stockage SAN, apportent les bénéfices suivants.
-
Réduction des coûts : une infrastructure hyperconvergée nécessite moins de serveurs, moins d’appareils réseau, pas de baies de stockage externes. Cela représente des économies substantielles.
-
Réduction...
Répartition de charge réseau
1. Introduction
La répartition de charge réseau se fait dans Windows Server avec un autre type de cluster que les clusters de basculement. Dans ces clusters d’équilibrage réseau, les serveurs sont appelés des hôtes.
L’équilibrage de charge réseau est une fonctionnalité de Windows Server et non pas un rôle. C’est une fonctionnalité assez ancienne et qui a peu évolué. Microsoft y fait souvent référence avec l’acronyme NLB (Network Load Balancer). Elle se gère avec une console ou avec PowerShell.
Si un hôte tombe en panne, la répartition de charge se fait alors entre les hôtes restants et lorsqu’il est de nouveau disponible, il rejoint à nouveau le cluster de répartition, charge automatiquement et reprend sa part du trafic. La redistribution et le rééquilibrage prennent un temps de 10 secondes au maximum.
Un maximum de 32 hôtes peut être ajouté au cluster et l’ajout comme la suppression d’hôtes au cluster se font de manière transparente. Les hôtes doivent avoir des configurations IP statique, l’équilibrage réseau désactive le protocole DHCP sur les cartes réseau pour lesquelles il est configuré.
Microsoft recommande d’avoir au moins deux cartes réseau par hôte, un pour le réseau de gestion et un pour l’accès des clients. C’est sur les cartes d’accès au réseau client que l’équilibrage de charge doit se faire. De plus, certains modes de fonctionnement de l’équilibrage de charge nécessitent deux cartes réseau.
La manière dont le cluster va équilibrer la charge sera définie par des règles appelées des « filtres » dans la terminologie Microsoft.
Il existe un autre type d’équilibrage de charge réseau dans Windows Server, c’est le Software Load Balancer. Celui-ci est spécialisé pour faire de l’équilibrage dans des réseaux virtuels et pour gérer le trafic vers des machines virtuelles.
2. Préparation du lab
Pour mettre en œuvre l’équilibrage, nous allons utiliser deux serveurs avec...
Clusters étendus
Les clusters étendus, aussi appelés stretch clusters sont des clusters de basculement qui s’étendent sur plusieurs sites géographiques distants et qui peuvent basculer d’un site géographique à un autre. Il est difficile de démontrer ici la création de clusters étendus, étant donné les ressources physiques que cela demande, mais nous allons en passer en revue les principaux concepts.
1. Présentation et concepts de base
Dans un cluster étendu, le basculement d’un node se fera à l’intérieur d’un même site, et si tous les nodes d’un site tombent, alors le basculement des charges de travail se fera vers les nodes de l’autre site. Dans un cluster étendu, les nodes des deux sites pourront être actifs en même temps.
Il est possible de faire des clusters étendus avec un minimum de deux serveurs, un par site. Dans ce cas, le basculement dans le même site ne sera pas possible. Au maximum, nous pouvons mettre 64 serveurs dans un cluster étendu.
Cela implique une réplication du stockage d’un site vers l’autre, ce qui est assuré par la fonctionnalité de réplica de stockage que nous avons vue dans le chapitre Le stockage de cet ouvrage.
Le réplica de stockage d’un cluster étendu supporte...



