
Playbooks, rôles et notions avancées
Objectifs du chapitre et prérequis
Après avoir vu le fonctionnement des playbooks et rôles dans Ansible, vous allez pousser un peu plus loin l’investigation sur le fonctionnement des rôles.
1. Contexte et prérequis
Ce chapitre étant un approfondissement des thématiques abordées précédemment, le lecteur doit être familiarisé avec les notions de rôles et de playbooks ainsi qu’avec l’utilisation des inventaires.
Vous aborderez quelques problématiques que vous pourriez rencontrer, comme par exemple, la gestion des interpréteurs Python locaux ou la notion de scalabilité de service. Autre nouveauté, vous utiliserez une machine basée sur Debian pour la répartition de charge.
2. Fichiers téléchargeables
Vous pouvez récupérer les exemples sur le repository GitHub suivant : https://github.com/EditionsENI/ansible
Vous pouvez également récupérer ces fichiers dans l’archive chapitre-08.tar.gz depuis la page Informations générales.
Gestion de Python sur les machines distantes
1. Introduction
Avant de reprendre vos travaux sur le wiki, vous allez étudier la gestion de la configuration de l’interpréteur Python sur les machines distantes. En effet, pour la plupart des opérations, Ansible passe par des microprogrammes Python déposés sur les machines à administrer.
Par la suite, vous aborderez les méthodes à suivre en cas d’absence de l’interpréteur Python ou d’un interpréteur installé dans des chemins non standards (ex. : Python 3).
L’interpréteur Python 2 n’est plus supporté depuis le 1er janvier 2020. Néanmoins, ce dernier reste très présent dans les parcs de machines existants. Notamment, il s’agit de l’interpréteur Python par défaut sur les distributions Red Hat Enterprise ou CentOS 6 et 7.
2. Préparation de l’inventaire
Premièrement, vous allez préparer votre inventaire et vous assurer que la communication SSH se passe bien. Vous allez utiliser une nouvelle machine nommée haproxy1 que vous allez ajouter dans l’inventaire wiki.yml dans un nouveau groupe intitulé haproxy. Après modification, le fichier devrait avoir le contenu suivant :
apache:
hosts:
apache1:
php_install: yes
mysql:
hosts:
mysql1: {}
haproxy:
hosts:
haproxy1: {} Comme indiqué plus tôt, pour vous assurer que la communication se passe bien, vous...
Scalabilité et répartition de charge
1. Contexte
Avant de voir en détail le fonctionnement des interpréteurs Python, vous aviez vu dans le chapitre précédent comment installer un wiki dans un cas simple (une machine pour chaque fonction). Dans ce qui va suivre, vous allez répondre à un besoin courant : augmenter votre capacité d’accueil sur l’application MediaWiki ainsi que la nécessité de rendre la brique Apache redondante.
Vous aborderez quelques techniques qui vont vous permettre de répondre à ces thématiques et notamment :
-
l’ajout de serveur (scalabilité) ;
-
la mise en œuvre d’un répartiteur de charge (pour la répartition de charge et la tolérance de panne) ;
-
la réalisation des mises à jour par vague (rolling update) ;
Pour le répartiteur de charge, vous vous appuierez sur le produit haproxy qui est un produit très utilisé pour ce genre de besoin. Il vous permettra de gérer plusieurs choses :
-
la répartition de charge ;
-
la tolérance de panne ;
-
la capacité de sortir une instance Apache pour y intervenir ;
-
la visualisation de l’activité des serveurs.
Tous les aspects du logiciel haproxy ne seront pas abordés. Ce livre ne présente que les fonctions nécessaires à faire fonctionner un exemple simple.
2. Origine du besoin
Mais d’où vient ce besoin de scalabilité et répartition de la charge ? Comme évoqué plus tôt, imaginons que vous ayez de plus en plus de personnes qui se connectent sur ce wiki. Le trafic augmentant, vous...
Ajout d’un répartiteur de charge
1. Pourquoi ajouter un répartiteur de charge ?
Votre nouveau serveur Apache est prêt, mais vos utilisateurs ne peuvent pas en bénéficier. En effet, les utilisateurs continuent d’utiliser l’URL qu’ils connaissent. Dans pareil cas, il faut ajouter un mécanisme de répartition de charge et indiquer à vos utilisateurs de mettre à jour leur signet.
2. Différence entre Ubuntu/Debian et Centos/Red Hat
Par la suite, vous aborderez l’installation d’un répartiteur de charge sur la machine haproxy1. Cette dernière se chargera de router le trafic sur les deux machines Apache. Comme indiqué un peu plus tôt, cette machine ne sera pas basée sur une distribution CentOS mais sur une distribution Ubuntu Server en version 20.04 LTS.
Le changement principal, dû à l’utilisation d’une distribution dérivée de Debian, viendra du remplacement des appels au module yum par des appels au module apt. Les options de ces deux modules sont identiques.
Une autre différence entre ces deux familles de distribution viendra du comportement par défaut du gestionnaire de package. Dans le cas d’une Debian ou dérivée, l’installation du package d’un serveur provoquera le démarrage automatique du service associé. Sur les dérivés de Red Hat, la tendance est plutôt d’installer le package serveur et de le laisser à l’arrêt.
Cette différence de comportement devra être prise en compte dans la suite du développement de vos playbooks. Sous Debian, les démons seront déjà...
Quelques bonnes pratiques à suivre
Le wiki est installé et tout fonctionne. Mais il est toujours possible de faire mieux. Dans ce qui va suivre, vous allez revenir sur certains points que vous avez survolés pour prendre le temps de les approfondir.
1. Contrôler le lancement des handlers
Un des premiers points que cet ouvrage vous propose de revoir concerne la gestion du déclenchement des handlers. En effet, jusqu’à maintenant, ces derniers se sont déclenchés quand ils le voulaient. Néanmoins, dans certains cas, il est préférable de gérer le moment de ce lancement.
Si on se penche sur le cas de l’installation et de la configuration de Haproxy, on se rend compte qu’il est souhaitable de gérer ce moment. En effet, en reprenant les tâches déroulées durant cette installation, vous retrouvez la réalisation des opérations suivantes :
-
Installer le package haproxy.
-
Déposer la configuration du Haproxy avec notification du handler de redémarrage.
-
Activer le service (sans changement, du fait que le service était démarré automatiquement par l’installation du package).
-
Déclencher le redémarrage du Haproxy.
Pour résumer, vous réalisez d’abord l’activation du service pour faire tout de suite après un arrêt/relance. Si vous aviez eu une machine basée sur Red Hat, ce redémarrage aurait été inutile.
En revanche, si vous aviez été en mesure de déclencher l’arrêt/relance avant l’activation du service, vous auriez supprimé une opération d’arrêt/relance inutile....
Mise à jour et réentrance de script
1. Contexte
Vous avez réalisé l’installation de MediaWiki, mais entre-temps une version 1.40.0 est sortie et vous aimeriez bien l’installer. Dans ce qui va suivre, vous allez aborder une problématique souvent rencontrée dans ce type d’application : gérer la mise à jour du schéma de base de données.
2. Gestion de la montée de version du schéma
Pour la mise à jour des fichiers statiques de l’application, il vous suffit de modifier le contenu du fichier mediawiki/configuration/defaults/main.yml afin de changer la valeur de la variable mediawiki_archive_ url pour passer à la version 1.40.0.
Ci-dessous, la déclaration correspondante :
# archive of mediawiki to download
mediawiki_archive_url: "https://releases.wikimedia.org/mediawiki/
1.40/mediawiki-1.40.0.tar.gz" Le lancement du playbook d’installation de MediaWiki ne sera pas réabordé (playbook install-mediawiki.yml). En effet, tout se déroule de la même manière que les fois précédentes. En revanche, il faut savoir que, d’une version à une autre, le schéma de la base de données change.
Dans le cas de MediaWiki, il s’agit d’un cas simple puisqu’il existe un script qui permet de gérer cette montée de version. Il s’agit du script nommé update.php qui se trouve dans le sous-répertoire maintenance. Le lancement de cette opération se fera après la création du fichier LocalSettings.php (le script de mise à jour en a besoin pour fonctionner).
Actuellement, vous n’avez aucune...
Mise à jour par roulement (rolling update)
1. Contexte
Vous avez un playbook qui s’exécute correctement et vous avez maintenant des serveurs à mettre à jour. Dans ce cadre, vous n’avez pas forcément envie de tout casser sur tous les serveurs en même temps. Ansible offre pour cela un mécanisme simple de lancement par vague.
2. Présentation du mécanisme
Prenons un cas simple : la mise à jour d’une vingtaine de machines. Vous avez des impératifs : il ne faut surtout pas d’indisponibilité de plus de 3 machines à la fois et surtout que l’installation s’arrête à la moindre anomalie.
Dans ce cas simple, le mot-clé serial est là pour répondre à ce besoin. Dans le cas présent, il faudra le positionner à 3 au niveau du playbook.
Si vous reprenez le playbook install-mediawiki.yml, le contenu du fichier devient le suivant :
- name: "MediaWiki db configuration"
hosts: mysql
gather_facts: no
tags: [ "mariadb", "mysql" ]
roles:
- role: "mediawiki/mariadb"
- name: "MediaWiki apache configuration"
hosts: apache
# 3 hosts at a time
serial: 3
tags: "apache"
gather_facts: no
roles:
- role: "mediawiki/configuration" Dans le cas où vous voudriez mettre à jour seulement un serveur, puis 3, puis 10, vous pourriez utiliser la syntaxe suivante :
# one...Inclusion et réutilisation
1. Contexte
La notion de rôle est intéressante pour réutiliser du code Ansible existant. Dans les chapitres précédents, l’utilisateur a abordé les techniques suivantes :
-
Application d’une liste de rôles (à l’aide du mot-clé roles dans un playbook).
-
Utilisation des métadatas (contenu du fichier meta/main.yml).
-
Inclusion de code existant (instruction include).
Bien que complets, ces mécanismes peuvent parfois être un peu limités, surtout dans un contexte complexe. Pour répondre à ces problématiques, Ansible offre les mécanismes suivants :
-
Inclusion de rôle (instruction include_role).
-
Inclusion dynamique de code (instruction include_tasks).
-
Inclusion statique de code (instructionimport_tasks).
Le mécanisme d’inclusion de rôle a été abordé précédemment afin de simplifier l’ordonnancement de tâches. La suite sera consacrée à mettre en lumière les différences entre les modes d’inclusion import_tasks et include_tasks.
2. Inclusion statique de tâches
Pour la suite des tests, l’utilisateur va créer un playbook simple procédant à l’affichage d’un message. Ci-dessous l’instruction permettant de réaliser cette opération :
- debug: msg="test" Sauvegardez cette instruction dans le fichier test.yml.
En plus de ce fichier, un playbook va être créé. Ce dernier va inclure de manière statique le fichier test.yml et s’exécutera sur la machine localhost.
Ci-dessous le code correspondant :...
Ansible Galaxy
1. Présentation du site
Vous l’avez vu, les rôles sont un moyen de mettre en commun du code pour l’installation de programmes. Ansible Galaxy permet de répondre à une autre problématique : centraliser et trouver des rôles Ansible déjà écrits.
La première étape va consister à se rendre sur le site : https://galaxy.ansible.com/
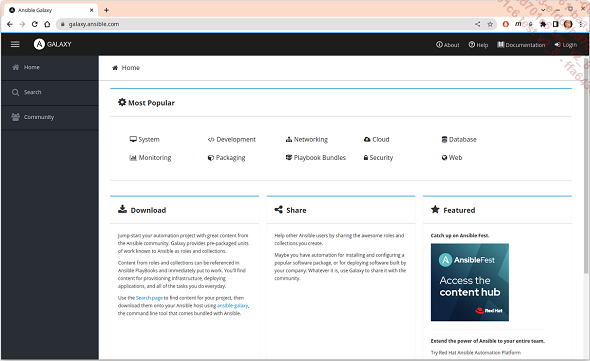
Racine du site web Ansible Galaxy
Ce site met à disposition un moteur de recherche vous permettant de trouver les rôles mis à disposition par la communauté :
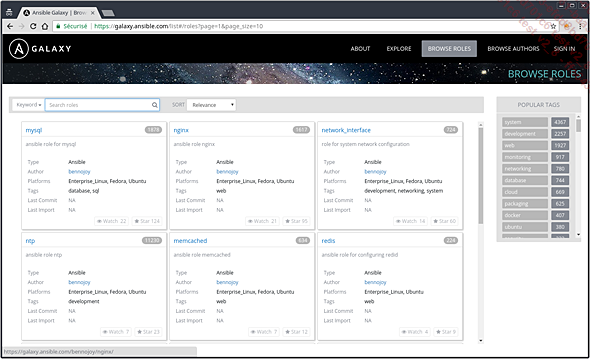
Moteur de recherche du site Ansible Galaxy
Le lien Browse roles vous permettra de faire des recherches dans les rôles existants :
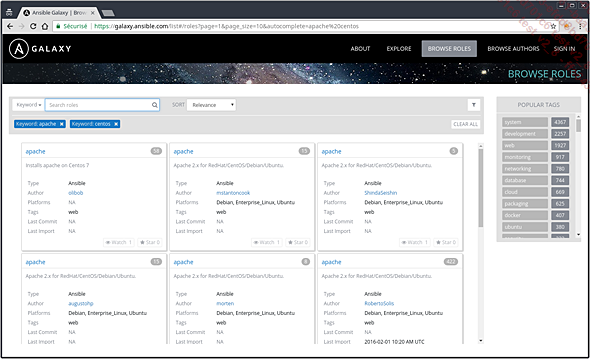
Recherche d’un rôle pour installer Apache sur CentOS
2. Recherche d’un rôle
Une autre solution pour rechercher un rôle est de passer par la commande ansible-galaxy en utilisant l’option search. Il est également possible de filtrer avec le nom d’un contributeur.
Pour cela, vous pouvez passer par l’option --author suivie du nom de l’auteur.
Vous rechercherez un rôle pour installer java publié par l’utilisateur viniciusfs.
Ci-dessous la commande correspondante :
$ ansible-galaxy search java --author viniciusfs Ci-dessous le résultat de cette commande :
Found 1 roles matching your search:
Name Description
---- -----------
viniciusfs.java Installs Java OpenJDK in CentOS/RHEL systems. Avant l’installation d’un...