
La conteneurisation et l'architecture microservice
Introduction
Docker et la conteneurisation de manière générale sont devenus pratique courante et résolvent bien des problèmes depuis l’avènement de ces technologies : déploiement, isolation des applicatifs, environnement homogène... Si votre application fonctionne sur votre machine avec des conteneurs, elle fonctionnera assurément sur vos environnements de déploiement.
La technologie des conteneurs se rapproche de la virtualisation tout en étant beaucoup plus légère : un conteneur n’embarque pas forcément un système d’exploitation. De par cette caractéristique très importante, les conteneurs sont ainsi plus appropriés pour rendre portables les applications (d’une machine à une autre ou d’un cloud à un autre) que les VM.
Ce chapitre traitera d’une des technologies les plus populaires pour la conteneurisation : Docker. Natif à Linux et récemment porté à Windows, Docker est aujourd’hui extrêmement répandu et aide les entreprises dans leurs déploiements. Docker permet également de construire des architectures d’entreprises plus complexes à base de conteneurs et ceci grâce aux orchestrateurs. Ce chapitre traitera du plus connu et open source : Kubernetes. Avec tout ceci, les architectures microservices...
Les bénéfices de Docker
Docker est une technologie issue du monde open source à la base. L’entreprise de la Silicon Valley exploite en effet plusieurs composants du noyau Linux afin de concevoir ses conteneurs (LXC, Libvirt...).
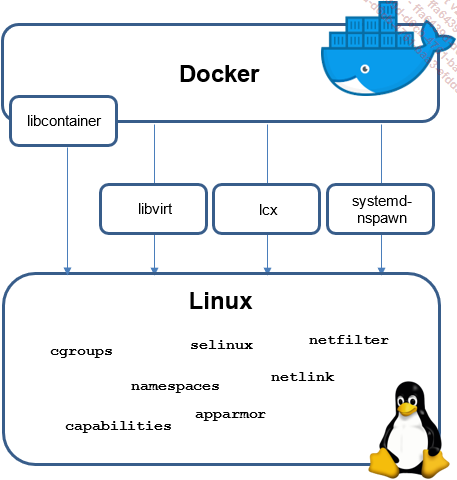
Architecture de Docker
Lancé par le Français Solomon Hykes, Docker permet de faciliter les déploiements d’application et la gestion du dimensionnement de l’infrastructure. Cette technologie s’appuie sur une brique d’API standard (LXC sur Linux et Windows Server Container sur Windows) afin de fournir une couche d’abstraction permettant aux conteneurs de s’exécuter sur n’importe quelle machine. Docker a l’avantage d’être bien plus léger qu’une machine virtuelle. Le lancement d’un conteneur est également plus rapide, ce qui en fait une solution privilégiée pour le déploiement de ses applications.
Docker ne fait pas qu’aider les entreprises dans leurs déploiements, il permet également d’accélérer les évolutions des écosystèmes cloud, et cela, Microsoft, Amazon ou encore Google l’ont bien compris. En effet, avec les conteneurs, il est très facile de déployer les services cloud on-demand. Par exemple, il est judicieux de conteneuriser les bases de données (MySQL, SQL Server...) afin de les déployer très rapidement selon la demande des utilisateurs.
Cette technologie apporte une réponse concrète à certains scénarios de développement. Par exemple, vous souhaitez tester une nouvelle version d’un framework sur votre applicatif ? Très simple, Docker est fait de plusieurs images Docker qui s’empilent pour créer votre image Docker, il suffit donc de remplacer la couche souhaitée par la nouvelle version afin d’essayer votre application. Avec une VM, cela devient compliqué de changer de version, car il faut désinstaller, puis installer la nouvelle version. Le temps perdu peut être conséquent.
Il en va de même pour la mise en production des applicatifs. Avec Docker, si l’application fonctionne sur votre machine, vous serez certain qu’elle fonctionnera sur l’environnement de production. Docker permet d’encapsuler toutes les dépendances...
Choisir Kubernetes comme orchestrateur
Docker est une technologie nous permettant de construire des applicatifs encapsulés dans des conteneurs et exportables d’un environnement à un autre avec peu de difficulté. Nous commençons donc à construire des sortes d’unités applicatives, manipulables très facilement, se lançant et s’arrêtant avec une simple commande Docker. Cette simplicité de gestion des conteneurs nous amène à construire de plus en plus d’applicatifs sous Docker, conduisant les équipes de développement à concevoir un nouveau type d’architecture : les microservices.
Les microservices nous permettent de concevoir des applications plus petites, focalisées sur un domaine fonctionnel bien précis de l’ensemble du système. Au vu de la légèreté des conteneurs, l’objectif des microservices est de faire fonctionner plusieurs conteneurs côte à côte afin d’encaisser au maximum les charges induites par l’utilisation du système d’information.
La gestion de plusieurs conteneurs devient ainsi une problématique beaucoup plus grande que par le passé. Peut-on faire fonctionner plusieurs conteneurs différents côte à côte ? Comment gérer la création/suppression des conteneurs de manière automatique selon la charge ? Afin de répondre à ces problématiques, Google a rendu open source un outil qui permettait justement à l’entreprise de gérer ses conteneurs en interne sur lesquels fonctionnaient ses applications : Kubernetes.
Kubernetes est une plateforme d’orchestration open source de conteneurs permettant entre autres d’automatiser le déploiement et la gestion d’applications multiconteneurs scalable. Kubernetes fonctionne de pair avec Docker : votre application fonctionne dans une image Docker, cette image va être gérée par Kubernetes afin de s’assurer que l’image, répliquée X fois selon les usages, fonctionne correctement.
L’orchestrateur est cependant compatible avec n’importe quelle technologie de conteneur conforme au standard Open Container Initiative. Docker a également développé son propre...
Comment concevoir son architecture microservice ?
L’architecture microservice est un type d’architecture logicielle émergeante tentant de répondre aux problématiques des applications dites monolithiques, à savoir : développement fastidieux, aucune flexibilité, difficulté de déploiement, zéro scalabilité... Le principe des microservices est simple : on décompose l’application en plusieurs applications plus petites et plus autonomes gravitant autour d’un Business Domain. Tout l’intérêt des microservices est de se recentrer sur le métier et les problèmes fonctionnels que l’application tente de résoudre.
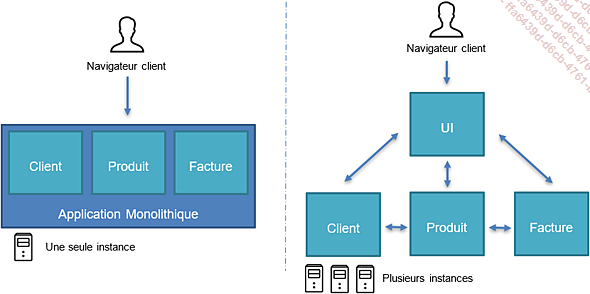
Différences entre application monolithique et microservice
Les microservices ont l’avantage d’être plus petits, et donc plus flexibles en termes de développement, de déploiement et de maintenabilité. Chaque microservice se doit de répondre à un aspect métier, ce qu’on appelle un contexte délimité (Boundary Context en anglais). Tout l’enjeu de l’architecture microservice est ici de s’assurer que la délimitation en domaine fonctionnel est suffisamment pertinente et cohérente pour garantir des microservices aussi petits que possible, mais suffisamment autonomes.
La taille des microservices est là le piège de cette architecture. Il paraît évident que plus les microservices sont petits, plus il sera facile de les gérer. Cependant, on peut très vite s’apercevoir que certains microservices communiquent beaucoup entre eux, car ils ont souvent voire systématiquement besoin des informations de l’autre pour fonctionner. Si un tel comportement est observé, cela veut dire que deux microservices ne doivent former qu’un.
Ceci est tout l’enjeu des contextes délimités. L’analyse préalable architecturale d’une solution en microservices doit aboutir à la séparation du business...
Utiliser les Remote Procedure Calls
Dans le cadre d’une architecture microservice, utiliser des API en REST pour les appels interservices présente plusieurs désavantages notables qu’il est important de prendre en compte lors de l’élaboration de l’architecture.
Tout d’abord, il faut noter qu’utiliser la technologie REST pour les API demande aux appelants de passer par toute la couche réseau ainsi qu’une désérialisation et sérialisation coûteuses pouvant entraîner une latence élevée - sans même parler du code qui, lui aussi, peut dégrader les temps de réponse (à juste titre ou non). Dans le cadre d’API exposée à l’extérieur ou pour des clients techniques, les API REST renvoyant du JSON sont pertinentes, car le format est lisible et facilement compréhensible par un client. Cependant, dans le cadre de communication interservices, cette compréhension n’est pas nécessaire.
Ensuite, naturellement, le contenu de la requête et de la réponse est transporté sous format texte (JSON ou autre format) et va ainsi surcharger la bande passante alors que, lors d’une communication interservices, cette surcharge n’est pas nécessaire : nous désirons simplement échanger des données entre deux services techniques sans se soucier du format, du moment que l’échange est performant.
C’est ici qu’interviennent les Remote Procedure Calls. Les Remote Procedure Calls (RPC) sont un type de protocole de communication qui permet à une application de faire appel à des fonctions ou des procédures exécutées sur un service distant, comme si elles étaient exécutées localement. Les RPC utilisent généralement un système de client-serveur, où l’application qui souhaite exécuter une fonction distante (le client) envoie une demande au serveur, qui exécute la fonction et renvoie le résultat au client.
Les RPC se basent sur un modèle de programmation similaire à celui des appels de fonction...
