
Fonctionnalités avancées
Gestion de données complexes
Dans un projet d’automatisation des tests avancés, une gestion efficace des données est primordiale. Il est généralement recommandé de séparer les données de test de la logique qui définit les scénarios de tests automatisés, en les externalisant pour une meilleure organisation et flexibilité. Externaliser consiste à stocker les données dans des fichiers externes, puis à les intégrer dans les fichiers de suites de tests ou de Resources.
Les données d’entrée dans Robot Framework peuvent être fournies au projet à travers divers formats de fichiers : Python (.py), YAML (.yml), JSON (.json) ou Excel (.xlsx). Chaque format de fichier répond à des besoins spécifiques, offrant une flexibilité adaptée au contexte du projet. Cette section mettra en avant le format YAML, choisi pour ses caractéristiques uniques et de ses cas d’utilisation variés. Les fichiers YAML se distinguent par leur simplicité et leur capacité à organiser des données hiérarchiques de manière claire et lisible. Cette structure les rend idéaux pour gérer des configurations complexes, souvent utilisées dans des environnements où les équipes collaborent sur des projets partagés. Les fichiers YAML sont également compatibles avec de nombreux outils DevOps, ce qui les rend précieux pour la gestion des paramètres dans les pipelines d’intégration et de déploiement continus.
Le format Excel par exemple est fréquemment utilisé dans les tests orientés données, une approche qui sera abordée dans la section Data Driven Development de ce chapitre, où des jeux d’informations volumineux et variés doivent être gérés. Excel permet de centraliser les données dans des tableaux structurés, facilitant ainsi l’édition et l’intégration dans des projets d’automatisation. Grâce à des bibliothèques comme DataDriver ou ExcelLibrary, les données des fichiers Excel peuvent être exploitées directement dans...
API Robot
Robot Framework n’est pas seulement un outil pour exécuter des tests automatisés ; c’est aussi un framework Python extensible doté d’une API puissante et riche. Cette API permet aux développeurs d’interagir directement avec les fonctionnalités internes du framework via du code Python, ouvrant la voie à une personnalisation avancée et à des extensions adaptées à des besoins spécifiques.
Dans cette section, nous allons découvrir ce qu’est réellement l’API Robot Framework, ses principales composantes, et comment l’utiliser efficacement dans vos projets.
L’API de Robot Framework est une collection de modules Python qui exposent les fonctionnalités internes du framework. Elle permet :
-
de créer ou de manipuler des fichiers de test et des suites de tests ;
-
d’interagir avec les résultats d’exécution ;
-
d’étendre les capacités de Robot Framework via des bibliothèques personnalisées ou des outils auxiliaires ;
-
d’automatiser des tâches liées à la gestion ou à l’exécution des tests.
Et bien d’autres fonctionnalités. Ces API sont accessibles directement en installant Robot Framework comme package Python, ce qui en fait un framework puissant pour les développeurs et les testeurs.
La documentation officielle de Robot Framework est accessible à l’adresse suivante : https://robot-framework.readthedocs.io/en/latest/. Cette section vise à mettre en lumière les API les plus pertinentes, accompagnées de quelques exemples d’utilisation pour chacune d’entre elles.
Avant de présenter les API les plus pertinentes et des exemples de scripts les utilisant, il convient de rappeler aux débutants en Python qu’un script peut être exécuté simplement à l’aide de la commande suivante :
python path/to/script.py Cette commande permet d’exécuter les scripts fournis dans cette section du livre afin de visualiser les résultats.
Voici une sélection des API les plus utiles.
robot
robot est le module principal pour interagir avec Robot Framework, adapté à la majorité des cas d’utilisation standard.
Voici quelques exemples d’utilisation...
Exécution parallèle
L’exécution parallèle des tests est un levier majeur pour optimiser les temps d’exécution, en particulier dans les projets de grande envergure où l’efficacité est primordiale. Robot Framework intègre une solution robuste à travers l’outil Pabot, conçu pour exécuter simultanément plusieurs suites ou cas de test. Sa capacité à gérer des contextes avancés, comme les tests massifs ou complexes, en fait un atout incontournable pour maximiser la productivité des équipes.
Pabot, une extension de Robot Framework, peut être installé à l’aide de la commande suivante :
pip install robotframework-pabot Pabot fonctionne de manière similaire à la commande robot, mais ajoute des options pour gérer les exécutions parallèles. Une utilisation simple de Pabot est la suivante :
pabot tests/ Avec tests/ un dossier contenant plusieurs fichiers .robot. Voici les options les plus pertinentes de Pabot :
-
--processes : détermine le nombre de processus parallèles à utiliser pour l’exécution des tests. Cela contrôle le degré de parallélisme, déterminant combien de suites ou de tests peuvent être exécutés simultanément.
-
--outputdir : définit le répertoire...
Création de rapports personnalisés
Robot Framework génère par défaut des rapports HTML et logs basés sur le fichier output.xml, qui centralise les résultats des tests. Cependant, il est souvent nécessaire d’aller au-delà des rapports par défaut en les personnalisant pour répondre à des besoins spécifiques, comme des tableaux de bord sur mesure ou des rapports simplifiés pour les parties prenantes non techniques. Cette section explore d’abord la fusion de rapports via output.xml, puis présente comment créer des templates HTML personnalisés pour un reporting adapté.
Lorsque les tests sont exécutés en parallèle ou en plusieurs lots, ils génèrent plusieurs fichiers output.xml. Ces fichiers peuvent être combinés en un seul, regroupant tous les résultats dans un rapport unique à l’aide de l’outil Rebot, inclus par défaut avec Robot Framework.
L’option --merge sera utilisée pour effectuer cette fusion :
rebot --merge output1.xml output2.xml output3.xml -o output_merged.xml Une fois que le fichier xml final est généré, il est possible, toujours avec le même outil Rebot, de générer des rapports HTML en utilisant l’option -r et des logs consolidés en utilisant l’option -l :
rebot -o final_output.xml -r final_report.html -l final_log.html output_merged.xml Voici quelques options supplémentaires, parmi les plus utilisées avec l’outil Rebot, accompagnées d’un exemple de commande pour chacune :
-
--exclude : exclut du rapport final les tests marqués avec des tags spécifiques.
rebot --exclude tag output.xml La commande rebot --exclude tag output.xml exclut des rapports générés tous les tests ayant comme tag tag. Cela permet de filtrer les résultats pour se concentrer uniquement sur les tests pertinents, tout en recalculant les statistiques globales en fonction des tests restants. Les fichiers report.html et log.html produits ne contiendront donc pas les tests exclus.
-
--splitlog : divise les logs détaillés en plusieurs fichiers pour une meilleure lisibilité et gestion.
rebot --splitlog output.xml La commande rebot --splitlog output.xml divise...
Data Driven Development
Le Data Driven Development (DDD) est une approche de test automatisé qui consiste à séparer les données de test des cas de test eux-mêmes. Plutôt que de coder des scénarios spécifiques avec des valeurs fixes, cette méthode permet de définir des cas de test génériques qui sont exécutés avec différentes valeurs d’entrée, provenant d’une source externe (par exemple, fichiers Excel, CSV, bases de données). Le cœur de cette approche repose sur un principe simple : un seul script peut couvrir une multitude de scénarios en modifiant uniquement les données d’entrée.
Un exemple concret illustrant l’intérêt de cette approche est l’automatisation d’un cas de test de virement bancaire impliquant des tests de virements entre différents types de comptes, tels que :
-
de compte courant à compte pro ;
-
de livret A à compte pro ;
-
de compte courant à livret A ;
-
de compte pro à compte épargne.
L’approche Data Driven Development s’avère idéale. Elle permet de concevoir un script de test générique, piloté par un ensemble de données variées représentant les différents cas. Les données d’entrée, telles que le type de compte source, le type de compte cible, et le montant du virement, sont injectées soit directement dans le cas de test, soit dynamiquement à partir d’une source externe, comme un fichier CSV, Excel ou JSON. C’est toutefois le nombre de jeux de données qui détermine combien de tests seront exécutés. Cette méthode offre une gestion centralisée des données, une maintenance simplifiée, et une couverture élargie des scénarios, tout en limitant la duplication des scripts. Par exemple, la modification du fichier de données permet de tester un grand nombre de combinaisons sans nécessiter de modification du script principal. Cette approche est particulièrement adaptée aux processus riches en variations, tels que les systèmes bancaires ou financiers.
Cette approche repose sur l’utilisation de templates pour structurer les tests, une notion abordée en détail dans...
Behavior Driven Development
L’approche Behavior Driven Development (BDD), souvent associée à Gherkin et à la structure Given-When-Then, est de plus en plus adoptée, notamment dans les projets agiles, en raison de ses nombreux avantages. Si son principal avantage réside dans la simplicité de sa représentation en langage naturel, son véritable atout est de fournir des spécifications exécutables, un avantage unique en son genre. Comme son nom l’indique, cette approche oriente le développement autour des user stories en décrivant les comportements attendus derrière chaque fonctionnalité. En intervenant dès les phases initiales du développement, elle favorise une meilleure implication et compréhension des user stories par toutes les parties prenantes du projet.
Une mise en œuvre correcte du BDD, telle que décrite dans les ouvrages officiels, repose sur trois étapes principales tout en respectant des principes fondamentaux.
1. Maturation des user stories avec la technique Example Mapping (découverte)
Cette étape consiste à structurer les user stories en format facilement transcriptible en Gherkin, en couvrant toutes les règles métier par des exemples et en clarifiant les incompréhensions. L’Example Mapping est une technique courante pour cela. Elle représente les user stories dans un tableau à quatre couleurs :
-
jaune : titre de la user story ;
-
bleu : règles métier ;
-
vert : exemples illustrant les cas couverts par chaque règle ;
-
rouge : questions non résolues soulevées lors des ateliers.
Ce tableau est rempli lors d’ateliers collaboratifs avec les parties prenantes (idéalement les 3 Amigos). Voici un exemple illustré sous forme de tableau Excel.
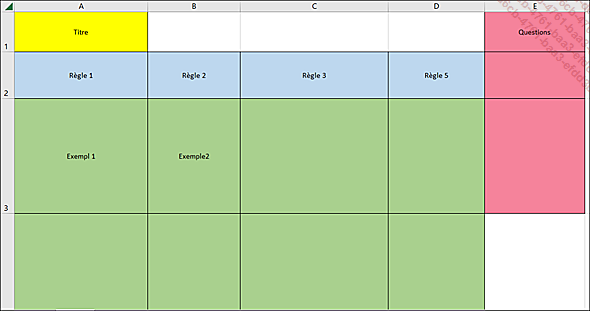
User story représentée sous format tableau rempli lors des ateliers d’Example Mapping
2. Transcription en Gherkin (ou formulation)
Cette étape consiste à convertir les exemples en syntaxe Gherkin. Pour simplifier cette transformation, il est conseillé de structurer...
Intégration à une chaîne CI/CD
Une chaîne CI/CD (Continuous Integration/Continuous Delivery) est un processus automatisé qui facilite le développement et la livraison de logiciels. Elle assure que chaque modification de code est rapidement testée pour détecter les erreurs (CI) et, une fois validée, automatiquement déployée dans les environnements de test ou de production (CD). Cette approche garantit des mises à jour fréquentes, fiables et sans interruption, tout en réduisant les risques d’anomalies.
Intégrer un projet Robot Framework à une chaîne CI/CD consiste à automatiser l’exécution des tests à chaque étape clé de développement logiciel, comme après chaque modification de code ou avant un déploiement en production. Cela inclut la configuration de l’environnement d’exécution des tests, le déclenchement automatique des scripts Robot Framework, la collecte des rapports générés (output.xml, report.html, log.html), et leur archivage ou visualisation dans l’outil CI/CD utilisé. Cette intégration permet de détecter rapidement les régressions, de garantir la qualité des livrables, et d’accélérer le cycle de livraison grâce à un processus fiable et reproductible.
Un job dans une chaîne CI/CD est une tâche spécifique et autonome. Par exemple, un job peut être dédié à l’installation des dépendances, à l’exécution des tests Robot Framework, ou à la génération de rapports. Chaque job correspond à une étape bien définie. Un pipeline est une suite organisée de jobs exécutés séquentiellement ou en parallèle pour atteindre un objectif global.
Voici les principales phases couramment présentes dans un job, accompagnées d’une indication sur l’implication de Robot Framework dans chacune d’elles.
1. Phase 1 : préparation de l’environnement
La phase de préparation de l’environnement dans un job CI/CD consiste à configurer les outils, les dépendances, et les environnements nécessaires à l’exécution. Pour Robot Framework...
Listeners
En Robot Framework, un listener est un composant qui permet de surveiller et d’interagir avec l’exécution des tests. Les listeners sont des bibliothèques Python spéciales qui implémentent des méthodes spécifiques pour capturer des événements déclenchés tout au long de l’exécution, comme le démarrage ou la fin d’un test, la génération de rapports, ou encore les erreurs.
Les listeners, une fois créés, sont activés via l’option de la ligne de commande --listener :
robot --listener nom_listener tests/ Un listener est une classe Python qui implémente les méthodes définies dans une interface spécifique de Robot Framework. Il repose plutôt sur une convention : Robot Framework s’attend à ce que certaines méthodes, avec des noms bien précis, soient définies dans la classe du listener. Si ces méthodes existent, elles seront appelées lors des événements correspondants. Voici une liste complète des méthodes que l’interface d’un listener peut implémenter, avec leurs descriptions :
-
start_suite : appelée au début de l’exécution d’une suite de tests. Cette fonction peut être utilisée pour enregistrer des informations sur la suite ou effectuer des actions initiales avant son démarrage.
-
end_suite : appelée à la fin de l’exécution d’une suite de tests. Elle permet de collecter des informations sur les résultats de la suite et de déclencher des actions après son achèvement.
-
start_test : appelée au début de l’exécution d’un test. Utilisée pour initialiser des ressources ou enregistrer des informations spécifiques au test.
-
end_test : appelée à la fin de l’exécution d’un test. Permet d’obtenir et de traiter le résultat du test ou de nettoyer des ressources associées.
-
start_keyword : déclenchée avant l’exécution d’un mot-clé. Cette fonction peut être utilisée pour suivre l’ordre ou la nature des mots-clés exécutés.
-
end_keyword : déclenchée après...
Parsers
L’option --parser dans Robot Framework est une fonctionnalité avancée introduite pour permettre l’utilisation de parsers personnalisés lors de l’exécution des fichiers de test. Cette option est utile si vous souhaitez modifier ou enrichir la façon dont Robot Framework interprète vos fichiers de test.
Les parsers personnalisés dans Robot Framework permettent d’adapter et d’enrichir l’exécution des tests pour répondre à des besoins spécifiques. Ils sont utiles pour interpréter de nouveaux formats de fichiers comme JSON, YAML ou XML, ajouter des métadonnées dynamiques telles que des tags ou des variables, et valider la qualité des fichiers de test en vérifiant la syntaxe ou la conformité aux règles métier. Ils peuvent aussi faciliter la conversion entre différents frameworks, comme TestNG ou Gherkin vers Robot Framework, et gérer des tests paramétriques en chargeant dynamiquement des jeux de données.
Un parser dans Robot Framework, tout comme un listener, est représenté par un fichier Python contenant une classe. Cependant, leur rôle et leur moment d’intervention diffèrent : un listener interagit avec les événements déclenchés pendant l’exécution des tests, tandis qu’un parser intervient en amont, avant l’exécution, pour interpréter et transformer les fichiers de test ou de ressources en une structure compréhensible par Robot Framework. Contrairement au listener, le parser s’appuie sur l’API de Robot Framework.Voici la structure minimale d’un parser, avec uniquement les éléments obligatoires :
class CustomParser:
EXTENSION = “robot”
def parse(self, source):
# Charger une suite de tests depuis le fichier source
pass -
Dans un parser on retrouve : attribut EXTENSION : cet attribut joue un rôle clé dans la création d’un parser personnalisé pour Robot Framework. Il indique quels types de fichiers le parser peut gérer. Obligatoire, cet attribut permet à Robot Framework...
Créer sa propre bibliothèque
Les bibliothèques dans Robot Framework ont été abordées précédemment, et il a été mentionné qu’il est possible de créer ses propres bibliothèques pour répondre à des besoins spécifiques. Ces bibliothèques peuvent être utilisées de manière similaire aux bibliothèques natives ou externes, en les important dans vos fichiers de tests pour accéder à leurs mots-clés. Dans cette section, nous allons explorer les différentes façons de créer une bibliothèque Python, selon le niveau de complexité et les besoins spécifiques.
Il est possible de créer une bibliothèque en utilisant simplement des fonctions Python, sans recourir à une classe. Cette méthode est idéale pour des bibliothèques simples avec un ensemble limité de mots-clés.
# my_simple_library.py
def hello_user (name):
return f"Hello, {name}!" Pour utiliser cette bibliothèque dans le fichier .robot il suffit d’importer le fichier Python, en indiquant son emplacement.
*** Settings ***
Library path/to/my_simple_library.py
*** Test Cases ***
Test Simple Library
${message}= Hello User John
Log ${message} Si le fichier de bibliothèque est situé dans le même répertoire que le fichier .robot, le nom du fichier suivi de l’extension .py peut être utilisé directement lors de l’importation.
*** Settings ***
Library my_simple_library.py
*** Test Cases ***
Test Simple Library
${message}= Hello User John
Log ${message} En cas de saisie manuelle du chemin absolu, il est essentiel de respecter la syntaxe en utilisant uniquement des slashs /, sans jamais employer d’antislashs \ ou de doubles antislashs \\.
*** Settings ***
Library EmplacementDossierTelecharge/Chapitre6/section10/
my_simple_library.py
*** Test Cases ***
Test Simple Library ...Robot Framework en action
L’objectif de cette section est de fournir des exemples concrets de projets adaptés à différents domaines métier. L’idée est que le lecteur puisse repartir avec un ensemble de projets fonctionnels, facilement compréhensibles et adaptables, qu’il pourra reprendre et réutiliser dans son quotidien professionnel ou à titre personnel. Ces projets couvrent divers cas d’utilisation, allant des tests d’applications web à l’automatisation de tâches bureautiques, en passant par les tests d’API et bien d’autres, permettant ainsi de comprendre l’application pratique de Robot Framework dans des situations réelles. Cette approche vise à offrir un point de départ solide pour l’automatisation des tests et des processus.
Il est important de souligner que, bien que les scripts de tests fournis aient été validés au moment de la rédaction de ce livre, ils pourraient ne plus être fonctionnels, car ils dépendent du système testé, qui est susceptible d’évoluer. Par conséquent, certains scripts pourraient nécessiter une maintenance afin de retrouver leur pleine fonctionnalité.
1. Tests d’applications web
Dans cette section, l’automatisation de plusieurs scénarios de tests sera abordée pour l’application Google. On commencera par la fonctionnalité de recherche sur Google, en testant différentes données de recherche afin d’évaluer la manière dont le moteur de recherche répond à diverses requêtes. Ensuite, un scénario sera automatisé concernant la fonctionnalité Google Store, simulant la navigation et l’interaction avec les produits proposés et l’ajout d’articles dans le panier.
a. Scénario 1 : test de la fonctionnalité de recherche valide sur Google
Dans ce scénario, l’objectif est de tester la fonctionnalité de recherche sur Google avec un terme de recherche valide. Ce test permet de vérifier que le moteur de recherche retourne les résultats attendus pour une requête courante. Le test se compose de plusieurs étapes : ouvrir Google, accepter les cookies, entrer le terme de recherche dans le champ dédié...
Résumé
Ce chapitre couvre des concepts avancés et des fonctionnalités spécifiques de Robot Framework, visant à répondre aux besoins de tests complexes et personnalisés. Il commence par la gestion de données complexes, en mettant l’accent sur l’utilisation des fichiers au format YAML, puis explore l’API Robot, démontrant comment manipuler des composants comme TestSuite pour maximiser leur potentiel. La section sur l’exécution parallèle via Pabot met en lumière l’optimisation des performances, suivie d’une présentation de la création de rapports personnalisés en combinant Python et les API Robot. Les approches Data Driven et Behavior Driven Development sont abordées en détail, avec une définition claire et des exemples d’implémentation dans Robot Framework. L’intégration dans une chaîne CI/CD est illustrée par un exemple de job spécifique à chaque outil. Le chapitre traite également des listeners, utilisés pour suivre les événements d’exécution, et des parsers, qui permettent d’analyser et de transformer dynamiquement les fichiers de tests. Enfin, un guide pratique montre comment créer des bibliothèques personnalisées, statiques ou dynamiques, tout en expliquant comment étendre...