
Valoriser ses données avec l’IA
Introduction
Un peu d’histoire tout d’abord …
Le terme « Intelligence Artificielle » (IA) est apparu dans les années 1960. Pour être plus précis, il a été introduit en 1956 lors du Dartmouth College Summer Conference par John McCarthy. Si le concept est alors lancé, l’IA ne décolle pas pour autant immédiatement et reste dans un premier temps uniquement théorique. Il a fallu attendre la fin des années 1960, lorsque la puissance de calcul et la disponibilité des données ont atteint un niveau suffisant, pour voir les premières expérimentations concrètes débuter. Dans les années 1960 et 1970, l’introduction de voies de recherche comme l’apprentissage automatique (Machine Learning), le traitement du langage naturel (NLP) et la vision par ordinateur apparaissent progressivement et tracent les grandes voies d’exploration de l’IA.
La véritable révolution commence en réalité dans les années 2000. Comme un écho à la loi de Moore (1965) qui stipulait alors que la puissance des ordinateurs - en fait le nombre de transistors - allait doubler chaque année avec un coût constant, tout s’accélère brutalement. La croissance de la puissance machine combinée à l’essor du cloud va en effet permettre une avancée considérable dans les capacités de calcul et un gisement de données. Ces deux ingrédients combinés rendent possible le traitement de vastes quantités de données pour l’entraînement des modèles d’IA.
Aujourd’hui, il est devenu compliqué voire impossible de parler...
L’utilisation de l’IA
Il est intéressant de regarder dans quels domaines l’IA (et tout particulièrement le Machine Learning) s’est imposée. Très clairement, il y a trois domaines dans lesquels l’IA a fait ses preuves et c’est d’ailleurs tout particulièrement dans ces domaines que les entreprises et éditeurs de logiciels investissent aujourd’hui :
1. La prise de décision (par rapport à des critères pas ou peu définis) qui permet de prendre des décisions basées sur un historique plutôt que des règles établies.
2. La vision par ordinateur (Computer Vision) qui permet à l’ordinateur de voir.
3. Le traitement de données textuelles (ou NLP comme Natural Language Processing) qui permet à l’ordinateur de comprendre et écrire des textes.
1. Prendre des décisions
L’aide à la prise de décision ou à la capacité de faire des choix est en quelque sorte l’essence de l’informatique moderne. Ce qui est nouveau et innovant avec l’IA, c’est de pouvoir effectuer des choix à partir de critères indéfinis.
Prenons l’exemple d’un diagnostic médical. Comme on le sait, poser un diagnostic peut être extrêmement complexe du fait du nombre très important de paramètres qui entrent en ligne de compte. Ces paramètres peuvent d’ailleurs être connus, inconnus, voire même biaisés (par le patient lui-même qui ne localise pas précisément sa douleur par exemple). Le rôle d’un algorithme de Machine Learning va être de consolider sans a priori tous les paramètres connus et de les confronter à une base de symptômes d’anciens patients afin de poser le meilleur diagnostic.
Dans un domaine tout à fait différent, il est à noter qu’aujourd’hui la plupart des systèmes de recommandations client sont basés sur des algorithmes de Machine Learning. Lorsque l’on navigue sur un site marchand (ou autre d’ailleurs), les données de navigation sont automatiquement collectées. Les choix, les actions et tout ce que l’on fait sur le site sont finement tracés afin d’être consolidés...
Le Machine Learning
Le Machine Learning est un sous-ensemble de l’IA. Le Deep Learning (apprentissage profond) est lui-même un sous-ensemble du Machine Learning. L’IA comporte beaucoup d’autres sous-domaines qu’il serait illusoire de couvrir dans un seul ouvrage. Mais voyons un peu comment une machine peut apprendre par l’expérience.
Commençons par le début : qu’est-ce que l’apprentissage automatique ?
1. Principe de l’apprentissage
Pour mieux comprendre, présentons une expérience simple. Soient deux pots A et B disposés sur une table. Sur cette même table, on trouve aussi trois pions de formes différentes : rond, carré, triangulaire. On va donc tout d’abord montrer comment ranger les pions dans les bons pots : c’est l’étape d’apprentissage proprement dite qui se répète plusieurs fois.
Cette étape implique que quelqu’un présente la bonne manière de faire, et que l’apprenti regarde. C’est le mode d’apprentissage que tout être humain utilise quand il regarde ou écoute quelqu’un d’expérimenté (comme un professeur) réaliser ou expliquer quelque chose.
Ensuite, on présente un pion au hasard à l’apprenti afin de voir s’il a bien appris.
L’expérience se déroule donc en deux étapes :
Étape 1 - l’apprentissage : on met les pions dans les bons pots
-
le pion rond va dans le pot A ;
-
le pion carré dans le pot B ;
-
et enfin le pion triangulaire dans le pot B.
Étape 2 - la prédiction : on présente un nouveau pion (carré par exemple) à l’apprenti
-
Il doit le mettre dans le pot B sans quoi l’apprentissage n’aura pas été suffisant ! Il faudra alors recommencer les explications.
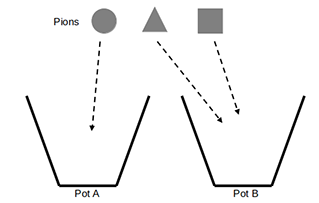
Phase d’apprentissage
-
Et si on présentait désormais un pion ovale (un pion qui n’a jamais été présenté lors de l’étape 1) ? Le choix n’est pas évident. Si on expérimentait une approche à base de règles, il y aurait fort à parier que cette exception serait mise de côté. Une chose est certaine : ce type de pion...
Les réseaux de neurones
Les réseaux de neurones sont incontournables aujourd’hui dès lors que l’on a besoin d’effectuer des traitements ou de prendre des décisions complexes basées sur des données. L’apprentissage profond via les réseaux de neurones, ou Deep Learning, est en effet un sous-ensemble du Machine Learning qui permet d’effectuer des tâches paraissant presque impossibles jusque-là pour une machine. Aujourd’hui, ce type d’algorithme est tout particulièrement utilisé dans le traitement de l’image mais aussi dans celui du langage.
1. Qu’est-ce qu’un réseau de neurones ?
L’idée initiale d’un réseau de neurones (proposé par McCulloch et Pits en 1943, puis Donald Hebb en 1949) est de reproduire le mode de fonctionnement du cerveau humain avec ses neurones, axones, synapses, etc. La réalité informatique actuelle impose cependant des limites à l’idée de propagation du signal. En effet, la conception des réseaux de neurones artificiels (NN - Neural Networks) reste assez éloignée de celle du cerveau humain, qui possède plus de 80 milliards de neurones et est beaucoup plus complexe. Cette idée de micro-unités de calculs (ou neurones) qui reçoivent et transmettent des signaux suivant certaines conditions reste l’élément fondateur de ces réseaux. Chaque neurone reçoit en effet des informations en entrée et produit un résultat en sortie. Ce dernier se propage ensuite à d’autres neurones via d’autres couches du réseau jusqu’à produire un résultat final.
Aujourd’hui, heureusement, il existe plusieurs frameworks pour le développement et la création de réseaux de neurones. Ces frameworks permettent de concevoir très facilement des réseaux de neurones et intègrent également toutes les fonctionnalités nécessaires à leur apprentissage, leur maintenance, leur suivi, etc.
Parmi les plus utilisés, on compte bien sûr TensorFlow (Google) et PyTorch (Meta).
2. Fonctionnement d’un neurone
Commençons par l’élément le plus petit du réseau : le neurone. Un neurone...
L’eXplainable AI
Le Machine Learning suscite aujourd’hui des craintes, notamment en raison de son aspect « boîte noire ». Contrairement à une approche déterministe, les algorithmes de Machine Learning reposent sur des méthodes probabilistes, statistiques ou, comme pour les réseaux de neurones, sur des techniques très mathématiques. Cette approche, totalement nouvelle et parfois déroutante, contraste fortement avec la logique claire et souvent explicable à laquelle les utilisateurs sont habitués pour prendre des décisions ou comprendre des problèmes. En somme, le manque de transparence du Machine Learning est fréquemment critiqué, voire bloque son adoption.
Son emploi et donc son adhésion passent par la confiance que doivent lui apporter ses « clients ». Pour gagner cette confiance, il est important d’expliquer comment et pourquoi un modèle a pris telle ou telle décision. Même s’il n’y a pas de parfaite réponse à cela, il y a plusieurs moyens d’expliquer comment un modèle réagit.
1. Pourquoi et comment expliquer un modèle ?
La méthode basée sur l’apprentissage s’éloigne complètement de l’approche que l’on pourrait qualifier de traditionnelle, à base de règles. D’ailleurs, cette dernière a, dans bien des cas, trouvé ses limites en s’apparentant avec le temps à un amoncellement d’exceptions plutôt qu’à des règles bien établies et maîtrisées. Cette transparence héritée de règles que l’on connaît et que l’on est capable de dessiner rapidement ne s’applique malheureusement pas dans le cas de l’apprentissage automatique. Avec le Machine Learning, il devient désormais complexe de dessiner et d’expliquer pourquoi et comment un modèle a pris telle ou telle décision. C’est un véritable changement culturel. Comme pour tout changement, il faut du temps pour que tout le monde l’accepte même si le Machine Learning semble offrir un nombre infini de nouvelles perspectives (son efficacité dans certains domaines n’étant d’ailleurs plus...
L’IA générative
Cela n’aura échappé à personne, la « Gen AI » (Generative AI) ou l’Intelligence Artificielle Générative est partout. Depuis la révélation de Dall-E, ChatGPT et autres MidJourney il est difficile de tourner le dos à cette nouvelle manière d’appréhender l’Intelligence Artificielle, à savoir la génération de contenu ! On remarquera ici l’emploi du terme « génération » plutôt que de celui de « création », ce qui est un point fondamental. L’IA telle qu’elle existe, n’est pas vraiment créative mais permet, grâce aux données avec lesquelles elle a été entraînée, de générer du contenu.
L’IA générative est donc un type d’Intelligence Artificielle capable de générer de nouveaux contenus, tels que du texte, des images, de la musique ou de la vidéo. Elle est souvent utilisée pour créer des contenus créatifs ou pour générer des données synthétiques. Elle repose sur des modèles statistiques qui apprennent à générer des données en se basant sur un ensemble de données d’entraînement. Par exemple, un modèle...
Bilan
|
À retenir |
|
|
Aller plus loin |
|
Marché et éditeurs |
|