
Comment effectuer vos prélèvements
Introduction
Le prélèvement des preuves, étape fondamentale à l’investigation numérique, doit prendre en compte l’intégrité des prélèvements ainsi que la chaîne de contrôle (chain of custody). Les sources de données sont hétérogènes, aussi ce chapitre est divisé en trois parties afin de couvrir au mieux toutes ces notions.
Nous commencerons par présenter comment réaliser vos prélèvements sur un hôte physique ainsi qu’en environnement virtualisé. Nous présenterons certains des hyperviseurs les plus représentatifs, les formats utilisés et comment les prélever.
Nous aborderons ensuite les conteneurs de type Docker puis nous finirons par une présentation des outils assurant la fonction de Triage complétée par les bonnes pratiques relatives au prélèvement.
Prélèvements physiques
1. Organisation
L’une des principales problématiques lors d’une investigation numérique est le prélèvement. Il est donc primordial de le préparer rigoureusement et d’évaluer la situation afin de s’organiser au mieux. Cela va notamment induire un ordre de prélèvement. Pour cela, la RFC 3227 Guidelines for Evidence Collection and Archiving (https://www.rfc-editor.org/rfc/rfc3227#section-2.1) propose l’ordre suivant :
-
les registres et mémoires cache ;
-
les tables de routage, la table ARP, le cache ARP, la table des processus, la mémoire vive ;
-
les fichiers temporaires ;
-
la mémoire de masse ;
-
les données de journalisation et de surveillance pertinentes pour le système en question, présentes sur un système distant ;
-
la configuration physique et la topologie réseau ;
-
le support dédié à l’archivage.
Dans bien des cas, l’ordre de prélèvement réalisé est en premier la mémoire vive (qui contient notamment les registres, la mémoire cache et les différentes tables) suivie par la mémoire de masse. La capture réseau est soumise à certaines contraintes :
-
L’ajout d’un boîtier TAP afin d’effectuer une recopie du trafic nécessite une coupure du réseau lors de son installation. Cela peut perturber les échanges métier et notre observation de l’attaquant.
-
La mise en place d’une recopie de port ou port mirroring nécessite la présence d’un administrateur, ce qui n’est pas toujours possible.
Les autres mémoires sont également importantes, mais dépendent du contexte de l’incident et des solutions en place. Ne pouvant couvrir tous les cas, nous ne les détaillerons pas.
Préalablement à tout prélèvement, il est nécessaire d’organiser son travail. Et pour cela quelques questions sont à se poser :
-
Quelles sont les caractéristiques de l’incident et comment préparer les postes des analystes en conséquence ?
-
Où et comment stocker ses futurs prélèvements ?
-
Où et comment stocker les artefacts issus de l’analyse ?
-
Quel...
Prélèvements en environnement virtualisé
1. Introduction
Les hyperviseurs sont des logiciels ou des modules d’un noyau qui permettent de virtualiser les ressources (CPU, mémoire et périphériques). Intel et AMD ont introduit les technologies de virtualisation Virtualization Technology for x86 (VT-x). AMD a aussi apporté la technologie AMD Virtualization (AMD-V) activable dans le BIOS/UEFI.
Il y a deux types d’hyperviseurs (figure 2), le type 1 s’exécute directement sur le matériel. Également appelée bare metal, cette catégorie comprend les produits suivants : VMware ESXI, Microsoft Hyper-V, KVM et Xen. Le second type s’exécute depuis un système d’exploitation hôte. Cette catégorie comprend, par exemple, VMware Player/Workstation/Fusion et VirtualBox.
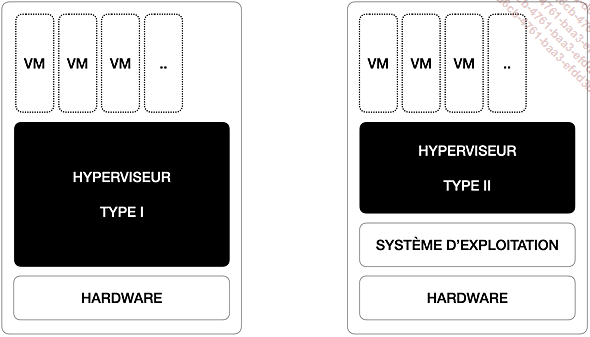
Figure 2 : représentation des différents types d’hyperviseurs
Nous présenterons les méthodes et outils permettant d’effectuer des prélèvements de la mémoire de masse et de la mémoire vive selon les hyperviseurs de type 1 en place. Les hyperviseurs de type 2 ne seront pas abordés, car à notre connaissance, il est rare de devoir les analyser dans le cadre d’une investigation numérique. Cette seconde catégorie, pour les produits VMware, s’étudie de la même manière que pour les hyperviseurs de type 1.
2. VMware ESXI
Aussi connu sous le nom d’ESX, VMware ESXI est un hyperviseur de type 1 développé par la société VMware. Cet hyperviseur est de type bare metal, c’est-à-dire qu’il s’installe directement sur le matériel. Longtemps basé sur la distribution Red Hat, VMWare a fait le choix de développer sa propre solution dans le but d’être indépendant. Il intègre donc son propre noyau comportant les spécificités nécessaires à l’hyperviseur. Il s’agit d’une des solutions à ce jour les plus répandues.
Chaque machine virtuelle possède ses propres formats de fichiers aussi bien pour la mémoire de masse que pour la mémoire vive.
-
Mémoire de masse : fichier ayant pour extension VMDK.
-
Mémoire vive : fichiers ayant pour extensions VMEM...
Conteneurs
Le terme Docker correspond à un ensemble de binaires permettant de créer, déployer et d’exécuter des conteneurs logiciels. Un conteneur fournit un espace cloisonné permettant à de nombreux programmes de s’exécuter de manière légère (empreinte mémoire faible), en limitant les effets de bord (mapping de ports réseau entre l’hôte et le conteneur). Cette solution est disponible sur Microsoft Windows, GNU/Linux et macOS.
La notion de conteneur n’est pas nouvelle, mais Docker l’a démocratisée grâce à sa simplicité, sa communauté et à son écosystème (notamment Swarm (https://docs.docker.com/engine/swarm/) et K8s (https://kubernetes.io/fr/)), proposant une industrialisation intéressante.
Si nous remontons un peu le temps, début des années 2000, Jails vit le jour sur FreeBSD (https://docs.freebsd.org/en/books/handbook/jails/). Il proposait un espace privé, sécurisé et séparé du reste du système. Depuis de nombreuses solutions sont venues remplir les rangs des alternatives intéressantes notamment Docker dès 2008.
Quelques solutions proposant une conteneurisation :
-
LXC (LinuX Containers)/LXD (https://linuxcontainers.org/lxc/introduction/), le noyau depuis la version 2.6.24 intègre la prise en charge de la conteneurisation proposant à un même hôte d’exécuter plusieurs instances Linux. LXC s’appuie sur des groupes de contrôle (cgroups) permettant de limiter et d’isoler les ressources d’un conteneur. LXD est une surcouche logicielle.
-
Podman (Pod Manager Tool, https://podman.io/), compatible avec les images Docker et les frameworks tels que Kubernetes, il ne s’appuie pas sur un daemon (processus fonctionnant principalement en arrière-plan, créé par le processus Init ou bien via l’appel système fork suivi par un arrêt immédiat du processus parent) gérant l’exécution des conteneurs à l’inverse de Docker et, de ce fait, se veut plus sécurisé (les conteneurs démarrent sans privilège root).
-
Buildah (https://buildah.io/) permet également de créer et lancer des conteneurs, et est compatible...
Triage
Le triage a pour objectif de répondre à la problématique du volume de données à traiter en ciblant les sources selon leur intérêt. Il y a deux types de triages, celui effectué sur un système en cours d’exécution (live triage) ou celui réalisé en laboratoire, nous parlerons alors de « post mortem triage ».
L’idée est d’identifier rapidement des artefacts afin de gagner du temps sur l’analyse approfondie des preuves. Pour rappel, l’ISO 27037:2012 intitulé Information technology - Security techniques - Guidelines for identification, collection, acquisition and preservation of digital evidence cadre les actions réalisées sur les preuves numériques. Il y est précisé notamment que les concepts de répétabilité (capacité à obtenir les mêmes résultats dans les mêmes conditions) et de reproductibilité (capacité à obtenir les mêmes résultats indépendants de l’analyste et du matériel) sont au cœur des actions réalisées par les analystes. L’étude Methods and tools of digital triage in forensic context: Survey and future directions [5] propose une enquête datant de 2017 sur les différentes formes de triage. Elle servira de base à cette section.
Il est intéressant de constater qu’il n’y a pas qu’une seule définition du triage, ce qui laisse supposer que cette approche n’est pas encore totalement mature. Il est également conseillé de ne pas considérer cette étape comme faisant automatiquement partie d’une investigation numérique, cela s’explique par le fait que les méthodes et outils utilisés ne respectent pas forcément les critères intrinsèques à l’investigation numérique.
1. Live triage
Le CFFTPM (Computer Forensic Field Triage Process Model) est un modèle [6] composé de six phases ayant comme objectif de rapidement trouver des preuves numériques et des artefacts pertinents, de guider et d’orienter l’investigation, d’identifier les victimes, les potentielles charges et d’évaluer avec précision le danger...
Bonnes pratiques
Cette section s’appuie sur notre expérience et, de ce fait, est non exhaustive. N’hésitez donc pas à compléter ce qui va suivre.
Une bonne pratique consiste à signer le prélèvement avec une clé asymétrique afin de garantir l’intégrité des données prélevées tout au long des analyses et des différents transferts qui en découlent.
Nous pouvons citer pour cela les outils suivants :
-
GNU Privacy Guard (GPG) ;
-
Secure/Multipurpose Internet Mail Extensions (S/MIME) ;
Prenons l’exemple de la signature du fichier de log contenant les empreintes numériques d’un prélèvement. La commande ci-dessous va dans un premier temps effectuer une copie bit à bit du disque /dev/sda avant de réaliser une empreinte numérique de type MD5 des fichiers issus de cette action. Ces empreintes sont les garants de l’intégrité des fichiers et seront conservées dans le fichier hash.log.
sudo dc3dd if=/dev/sda1 hof=/mnt/hgfs/Downloads/
dump.dd hlog=hash.log ofs=dump.000 ofsz=2G hash=md5 La commande gpg --list-keys vérifie que vous êtes en possession d’une clé de chiffrement sur votre poste. Si ce n’est pas le cas, il faudra exécuter la commande gpg -generate-key afin d’en générer une. La commande suivante va créer...
Références
[1] HOELZ, Bruno, RALHA, Celia, et MESQUITA, Frederico. Case-based reasoning in live forensics. In : IFIP International Conference on Digital Forensics. Springer, Berlin, Heidelberg, 2011. p. 77-88.
[2] KONDAM, Varun Reddy. Comparing SSD forensics with HDD forensics. 2020.
[3] PRANOTO, Wisnu, RIADI, Imam, et PRAYUDI, Yudi. Live forensics method for acquisition on the Solid State Drive (SSD) NVMe TRIM function. Kinetik: Game Technology, Information System, Computer Network, Computing, Electronics, and Control, 2020, p. 129-138.
[4] ZHANG, Shuhui, WANG, Lianhai, XU, Lijuan, et al. Virtual Machine Memory Forensics Method for XenServer Platform. In : 2019 International Conference on Networking and Network Applications (NaNA). IEEE, 2019. p. 302-308.
[5] JUSAS, Vacius, BIRVINSKAS, Darius, et GAHRAMANOV, Elvar. Methods and tools of digital triage in forensic context: Survey and future directions. Symmetry, 2017, vol. 9, no 4, p. 49.
[6] ROGERS, Marcus K., GOLDMAN, James, MISLAN, Rick, et al. Computer forensics field triage process model. Journal of Digital Forensics, Security and Law, 2006, vol. 1, no 2, p. 2.
[7] HITCHCOCK, Ben, LE-KHAC, Nhien-An, et SCANLON, Mark. Tiered forensic methodology model for Digital Field Triage by non-digital evidence specialists. Digital investigation, 2016, vol. 16, p. S75-S85.
[8] CANTRELL, Gary, DAMPIER, David, DANDASS, Yoginder S., et al. Research toward a partially-automated, and crime specific digital triage...