
Talend et les bases de données SQL
Introduction
Dans ce chapitre, il s’agit de voir comment les bases de données peuvent être utilisées dans Talend. Les bases de données dans Talend sont une source de données comme le serait un fichier plat (fichier Excel par exemple), sauf que les composants qui traitent les bases de données permettent beaucoup plus d’actions comme, par exemple, effectuer des requêtes pour ne sélectionner que les données intéressantes à l’aide du langage SQL (Structured Query Language).
Le langage SQL est un langage déclaratif (les étapes nécessaires à l’exécution d’une tâche ne sont pas dictées au programme). Il est séparé en :
-
DML : Data Manipulation Language (Langage de Manipulation de Données). Il regroupe les opérations de manipulation des données dans une base de données, telles que SELECT (sélection), INSERT (insertion), UPDATE (mise à jour) et DELETE (suppression).
-
DDL : Data Definition Language (Langage de Définition de Données). Il englobe les opérations de définition de la structure de la base de données, comme CREATE (création), ALTER (modification) et DROP (suppression).
-
DCL : Data Control Language (Langage de Contrôle de Données). Il concerne les commandes de contrôle d’accès...
Généralités sur le langage SQL
Le langage SQL permet :
-
la création de la base et des tables
-
l’ajout d’enregistrements sous forme de lignes
-
l’interrogation de la base
-
la mise à jour
-
le changement de structure de la table : ajout, suppression de colonnes
-
la gestion de droits d’utilisateurs de la base
1. Algèbre relationnelle syntaxe
SELECT * FROM table; Cette ligne de code signifie que vous demandez au composant de retourner toutes les colonnes (*) que contient la table appelée table.
2. Projection syntaxe
SELECT attr1, attr2, attr3 FROM table; Cette ligne de code signifie que vous demandez au composant de ne retourner que les colonnes ayant les attributs attr1 et attr2 et attr3 de la table appelée table.
3. Commentaire
Il peut être intéressant d’insérer des commentaires dans les requêtes SQL pour mieux s’y retrouver dans le cas de grosses requêtes complexes. Il existe plusieurs manières d’ajouter des commentaires dans le langage SQL, qui dépendent notamment du système de gestion de base de données (SGBD) utilisé et de sa version.
Commentaire double tiret (--)
Le double tiret permet de faire un commentaire jusqu’à la fin de la ligne.
Exemple
SELECT * -- tout sélectionner
FROM table1 -- dans la table "table1" 4. Commentaire multiligne (/* et */)
Le commentaire multiligne présente l’avantage de pouvoir indiquer où commence et où se termine le commentaire. Il est donc possible de l’utiliser en plein milieu d’une requête SQL sans problème.
Exemple
SELECT * /* tout selectionner */
FROM table1 /* dans la table "table1" */
WHERE 1 = 1 /* exemple en milieu de requete */ 1 5. Filtrer avec les opérateurs
a. L’opérateur AND
Il permet de joindre plusieurs conditions dans une requête. En gardant la même table que précédemment, pour filtrer uniquement les produits informatiques qui sont presque en rupture de stock (moins de 20 produits disponibles), il faut exécuter la requête suivante :
Exemple avec syntaxe généralisée
SELECT * FROM table
WHERE attribut='valeure' AND attribut2='valeure2';...Les modèles SQL dans Talend
Le nœud Modèles SQL rassemble tous les modèles SQL du système et permet d’en créer de nouveaux. Talend permet de bénéficier des Modèles SQL système puisque beaucoup de structures de requêtes sont standardisées à partir des mêmes approches.
Le nœud Modèles SQL dans Talend
Les Modèles SQL du système sont regroupés sous le nœud Modèles SQL dans le Référentiel de Talend. Différents types de modèles SQL standardisés sont disponibles :
Les Modèles SQL dans Talend
1. DeltaLake
DeltaLake est un environnement de stockage open source qui permet de construire une architecture Lakehouse Architecture avec des moteurs de calcul incluant Spark, PrestoDB, Flink, Trino, Hive et les API pour Scala, Java, Rust, Ruby, et Python.
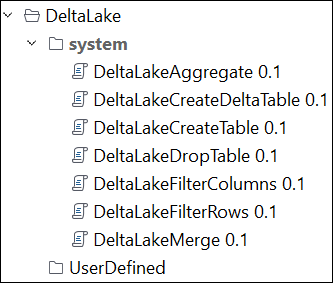
Les modèles SQL DeltaLake
2. Generic
Generic permet d’intégrer le service de synchronisation avec un système de base de données qui offre une connectivité ODBC (Open Database Connectivity).
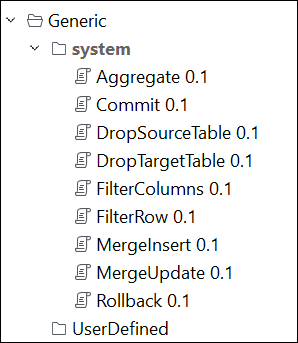
Les modèles SQL Generic
3. Hive
Hive est un datawarehouse Hadoop (entrepôt de données) open source. Cet entrepôt de données recueille ainsi des données d’un ou plusieurs types de sources de données pour analyser et extraire des données à l’aide de requêtes...
Job 32 : connecter Talend à une base de données
Avant de pouvoir effectuer des manipulations de bases de données sur Talend, la première étape consiste à établir une connexion avec la base de données. Pour cela, vous aurez besoin de collecter un ensemble d’informations spécifiques à la base de données..
Méthode
Allez dans Métadonnées et effectuez un clic droit sur Connexion aux bases de données.
Créez une nouvelle connexion.
Remplissez les paramètres de la base de données.
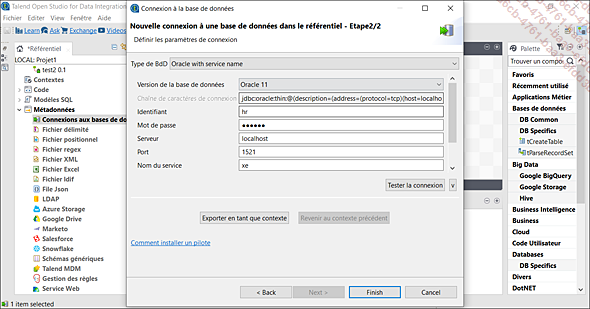
Paramètres de la base de données
Job 33 : importer des tables dans Talend
Après avoir connecté votre base de données à Talend vous aurez besoin d’importer les tables de cette dernière. Pour cela, il est nécessaire de récupérer et vérifier le schéma de la base de données, de sélectionner les tables à importer et surtout de définir le type des données de ces tables.
Méthode
Allez dans Métadonnées.
Allez dans db_connections.
Effectuez un clic droit sur votre connexion.
Sélectionnez Récupérer le schéma.
Cliquez sur Suivant.
Sélectionnez les tables à importer.
Cliquez sur Suivant.
Vérifiez que les informations sont bonnes (surtout sur les types de données).
Cliquez sur Terminer.
Vérifiez sur Schémas des tables que toutes les colonnes des tables sélectionnées ont été importées.
Job 34 : lier un fichier Excel et une BDD
Il est souvent nécessaire de travailler avec différentes sources de données à la fois, comme les bases de données et les fichiers plats par exemple, afin de compléter les données extraites de l’un ou de l’autre et ensuite charger les données intéressantes dans un autre fichier plat, une base de données ou même dans la log.
Méthode
Allez dans Palette.
Cherchez tMap (qui permet de faire la jointure).
Glissez le composant tMap entre le fichier Excel et la base de données se trouvant dans la fenêtre.
Effectuez un clic droit sur le fichier Excel.
Sélectionnez ligne, allez dans Main et tirez un lien du côté du tMap.
Effectuez un clic droit sur le tMap et allez dans ligne puis cliquez sur New Output.
Effectuez un lien jusqu’à la base de données.
Nommez le lien vers la base de données et cliquez sur oui.
Cliquez sur le composant tMap (à gauche se trouve la structure du fichier Excel, à droite la structure de la table).
Mappez les champs un à un (glissez un champ de gauche vers le champ qui lui correspond à droite).
Cliquez sur Appliquer puis sur OK afin d’obtenir un job fonctionnel qu’il sera possible d’exécuter en cliquant sur Exécuter.
Job 35 : BDD_EXTRACTION
Dans ce job Talend BDD_EXTRACTION, il s’agit d’aborder le premier job concernant la manipulation des bases de données.
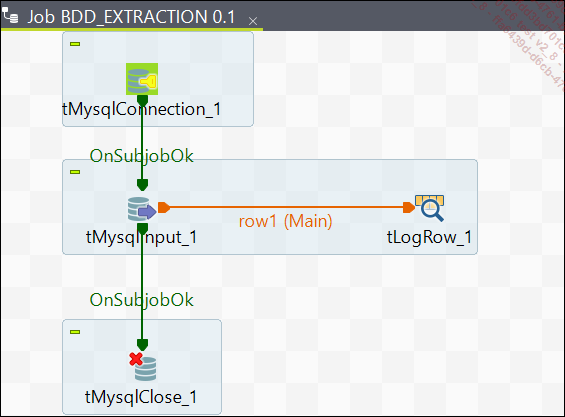
Job BDD_EXTRACTION
Le composant tMysqlConnection permet de vérifier que la connexion à une base de données MySQL s’est effectuée sans erreurs.
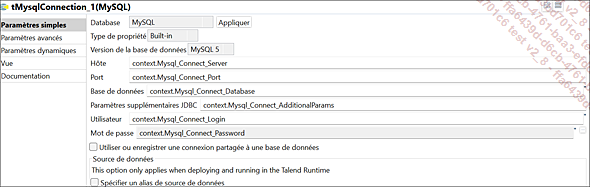
Paramètres du composant tMysqlConnection
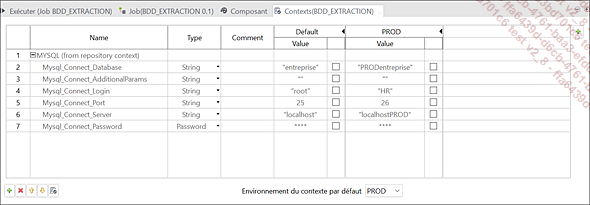
Contextes du composant tMysqlConnection
Le composant tMysqlInput permet de se connecter à une base de données MySQL et d’extraire les données à partir de celle-ci à l’aide d’une requête SQL (Structured Query Language).
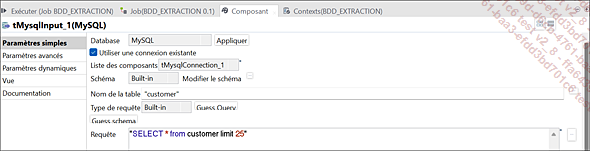
Paramètres du composant tMysqlInput
Dans ce composant tMysqlInput, une requête SQL a été mise en place et permet d’importer toutes les colonnes dans une limite de 25 lignes de données depuis la table customer de la base de données MySQL.
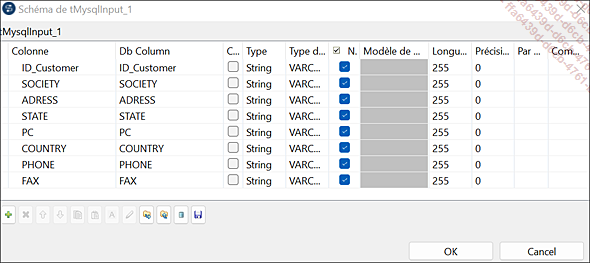
Schéma de la table Customer
Le composant tMysqlClose permet de se déconnecter de la base de données.
Paramétrage du composant tMysqlClose
Job 36 : CONNECT_AND_CHARGE
Le job Talend CONNECT_AND_CHARGE permet de se connecter à deux bases de données différentes Oracle et MySQL et d’extraire des données à partir de fichiers, afin de les charger dans les bases de données.

Job CONNECT_AND_CHARGE
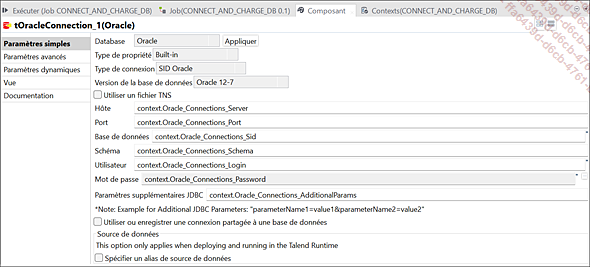
Paramètres du composant tOracleConnection_1
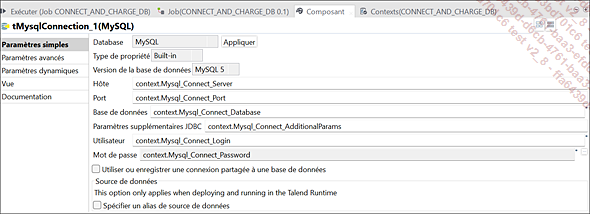
Paramètres du composant tMysqlConnection_1
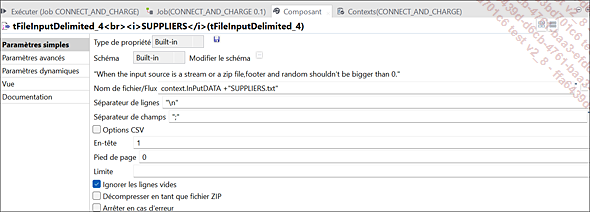
Paramètres du composant tFileInputDelimited_4 (SUPPLIERS)
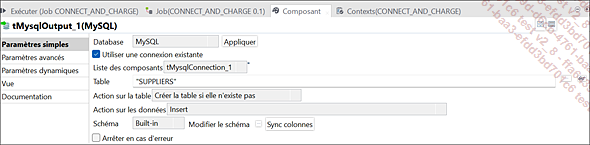
Paramètres du composant tMysqlOutput_1 (SUPPLIERS)
Une action a été spécifiée sur la table en demandant à Talend de créer la table SUPPLIERS si elle n’existe pas et d’y insérer les données extraites depuis le fichier SUPPLIERS.txt.
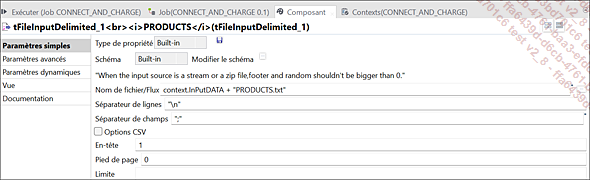
Paramètres du composant tFileInputDelimited_1 (PRODUCTS)
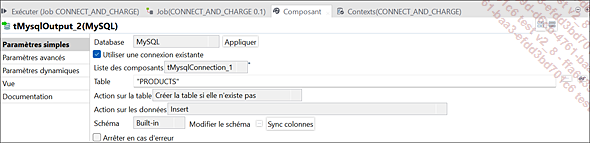
Paramètres du composant tMysqlOutput_2 (PRODUCTS)
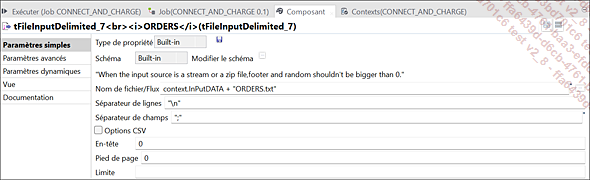
Paramètres du composant tFileInputDelimited_7 (ORDERS)
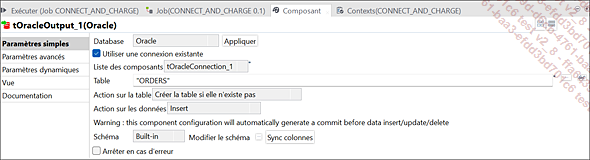
Paramètres du composant tOracleOutput_1 (ORDERS)
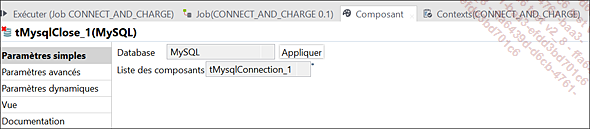
Paramètres du composant tMysqlClose_1
Paramètres du composant tOracleClose_1
Groupe de contextes MySQL
Groupe de contextes Oracle
Job 37 : JOIN_MULTI_BASE
Le job Talend JOIN_MULTI_BASE permet de se connecter à deux bases de données différentes Oracle et MySQL et d’extraire des données à partir de fichiers afin de les charger dans les bases de données. Une jointure sera également effectuée entre deux bases de données MySQL pour charger les données de celles-ci dans deux autres bases de données d’un type différent.
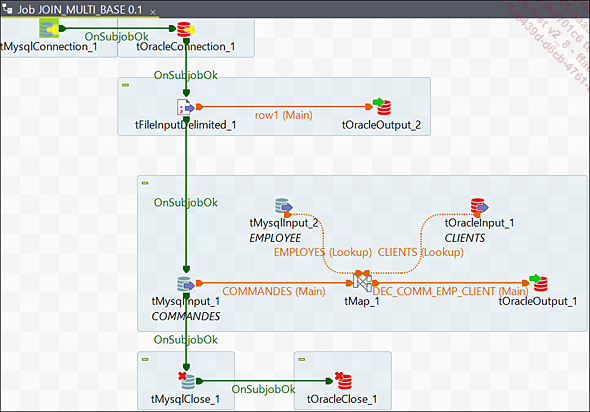
Job JOIN_MULTI_BASE
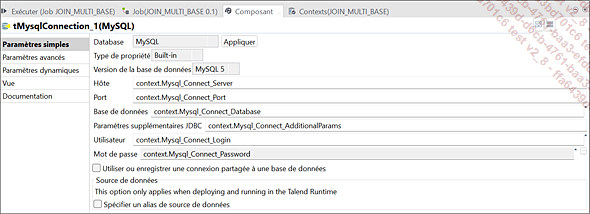
Paramètres du composant tMysqlConnection
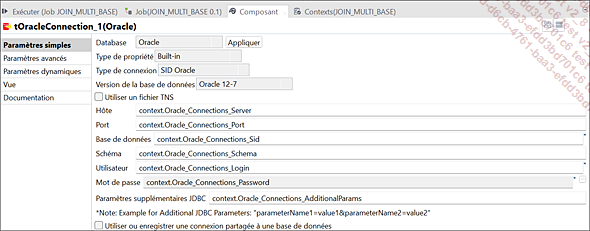
Paramètres du composant tOracleConnection_1
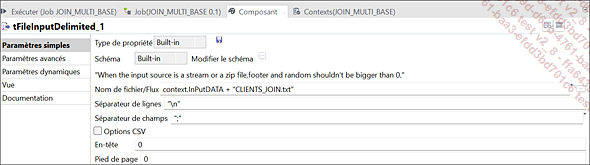
Paramètres du composant tFileInputDelimited_1
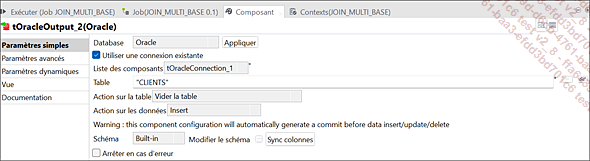
Paramètres du composant tOracleOutput_2
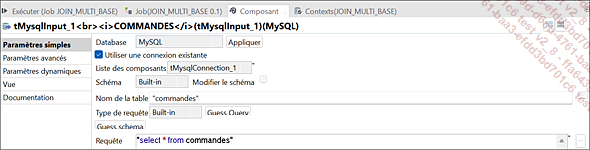
Paramètres du composant tMysqlInput_1 (COMMANDES)
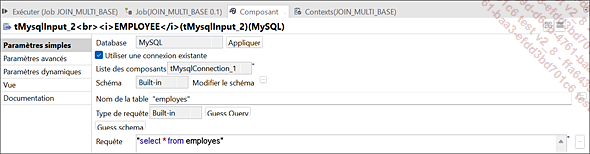
Paramètres du composant tMysqlInput_2 (EMPLOYEE)
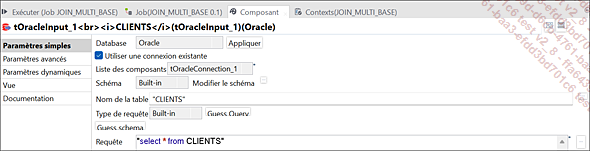
Paramètres du composant tOracleInput_1 (CLIENTS)
Les trois bases de données présentées [nommer ici les BDD] servent à extraire des données. La base de données tMysqlInput_1 (Commandes) a été alimentée par le fichier CLIENTS_JOIN.txt comme illustré dans le job précédent.
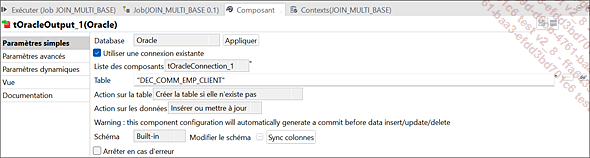
Paramètres du composant tOracleOutput_1
Le composant tOracleOutput_1 représente la base de données de destination dans le tMap. Il sera chargé avec les données provenant des trois bases de données : tMysqlInput_1, tMysqlInput_2 et tOracleInput_1....
Chargement Bulk (Massif)
Pour intégrer de fortes volumétries de données dans une base de données, il est préférable de charger les données en bulk (massivement) et non pas ligne à ligne. En effet, dans une insertion ligne à ligne, I’ETL appelle le SGBD pour lui transmettre une ligne, le SGBD réserve l’espace mémoire pour accueillir la ligne et l’insérer, et ces opérations se répètent en boucle jusqu’à réception de toutes les lignes sélectionnées, ce qui peut être vraiment très long. Dans le cas d’un chargement en bulk, I’ETL ordonne les lignes par paquets tandis que le SGBD se prépare en allouant de la mémoire en amont afin qu’il puisse recevoir toutes ces données. Ce mode d’intégration est donc idéal pour charger un DWH (Data Warehouse).
1. Chargement Bulk indirect
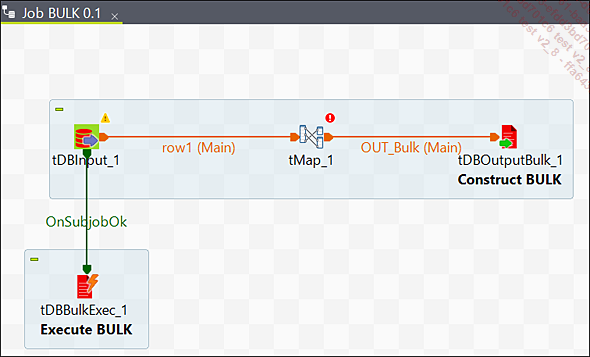
Job BULK
Une fois les données à charger récupérées avec le composant tOracleInput, il est possible de passer par le tMap afin de transformer les données si nécessaire, pour ensuite construire le fichier Bulk à l’aide du composant tOracleOutputBulk. Pour les chargements en Bulk, il est préférable de les exécuter directement sur le serveur d’exécution et d’y déposer le fichier Bulk...