
Adapter un réseau existant
Objectifs du chapitre et prérequis
Suite à la lecture des chapitres Réseaux de neurones à convolution et Bonnes pratiques pour l’entraînement, vous savez maintenant construire et entraîner un réseau de neurones à convolutions.
Dans ce chapitre, nous explorerons une approche puissante pour améliorer les performances de tels réseaux.
L’apprentissage par transfert tire parti des connaissances acquises par des modèles pré-entraînés sur de grandes quantités de données pour résoudre de nouvelles tâches. Nous examinerons en détail les principes et le fonctionnement de l’apprentissage par transfert, y compris la façon de choisir et d’utiliser des modèles pré-entraînés.
Nous décrirons également l’architecture et les performances de différents réseaux classiques tels que AlexNet, VGG, GoogLeNet, ResNet et EfficientNet.
Enfin, nous mettrons en pratique nos connaissances en adaptant un modèle pré-entraîné avec Keras pour améliorer le classifieur d’images de chats et de chiens développé au chapitre précédent.
Avant de lire ce chapitre, il est préférable d’avoir lu le chapitre Réseaux de neurones à convolution.
Apprentissage par transfert
1. Principe et motivation
Entraîner un réseau de neurones requiert à la fois une grande quantité de données, et beaucoup de temps et/ou de puissance de calcul.
L’apprentissage par transfert (transfer learning en anglais) permet de réutiliser un réseau entraîné sur autre jeu de données. Ceci permet de réduire la quantité de données nécessaires à l’entraînement, de diminuer le risque de surapprentissage, et d’accélérer la convergence.
Pour en comprendre l’idée générale, rappelons la structure générale des réseaux convolutionnels décrits dans le chapitre Réseaux de neurones à convolution.
Ces réseaux comprennent tout d’abord plusieurs couches de convolution et d’agrégation, dont le rôle est de détecter les caractéristiques de l’image d’entrée les plus pertinentes pour réaliser la classification. Les premières couches détectent les caractéristiques les plus simples et génériques, comme des bordures dans différentes directions, tandis que les dernières couches ont été entraînées à détecter des caractéristiques plus complexes et spécifiques au jeu de données sur lequel le réseau a été entraîné.
La seconde partie du réseau, contenant les couches complètement connectées, réalise la classification.
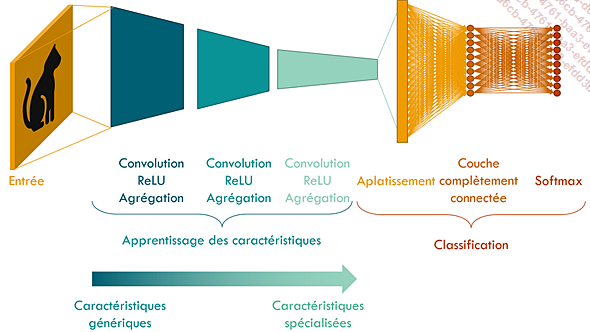
Représentation schématique d’un réseau de neurones
L’apprentissage par transfert fait l’hypothèse que les caractéristiques génériques apprises par les premières couches du réseau ne sont pas fortement liées au jeu de données, et qu’elles peuvent être réutilisées pour entraîner un réseau à réaliser une autre tâche de classification, c’est-à-dire avec des classes différentes, et un jeu de données différent.
Pour entraîner le réseau pour cette nouvelle tâche, il suffirait alors d’optimiser les paramètres des dernières couches.
Ayant moins de paramètres à...
Réseaux classiques
Nous allons détailler ici plusieurs réseaux connus.
Ces réseaux sont fréquemment utilisés. De plus, ils sont souvent utilisés comme bases pour le développement de nouvelles architectures.
Ce sont tous des réseaux de classification, mais nous verrons dans les chapitres Détection, Segmentation et Applications spécifiques comment ces réseaux peuvent servir de base pour résoudre d’autres problèmes de traitement d’images.
1. AlexNet
a. Architecture
Sorti en 2012, AlexNet est le premier réseau de convolution moderne.
Comme nous l’avons mentionné au chapitre précédent, c’est le premier réseau convolutionnel à avoir gagné le concours ILSVRC.
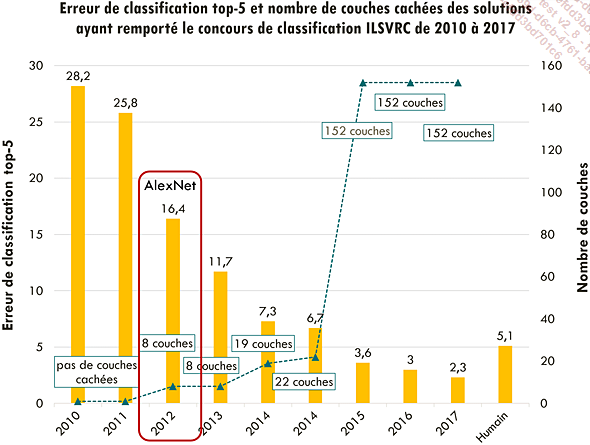
Évolution de l’erreur de classification réalisée par le modèle ayant remporté le challenge de classification ILSVRC. AlexNet est le premier réseau convolutionnel à avoir remporté le concours en 2012, avec une grande avance sur ses concurrents.
Son architecture est la suivante :
-
L’image utilisée en entrée est une image RGB de taille 224x224x3.
-
Cette image passe par une première couche de convolution, contenant 96 filtres de taille 11x11x3 (rappelons que la profondeur des filtres de convolution est toujours égale à celle de l’image d’entrée), avec un pas de 4. Grâce au pas supérieur à un, la dimension spatiale des images en sortie est réduite à une taille de 55x55x96. Cette couche est suivie d’une fonction d’activation ReLU.
-
L’image passe ensuite par une couche d’agrégation par maximum, qui réduit encore la taille de l’image à 27x27x96.
-
Une normalisation locale est ensuite appliquée au résultat. Cette couche, nommée local response normalization par les créateurs du réseau, est une opération spécifique qui n’a pas été utilisée dans d’autres architectures par la suite. Elle consiste à normaliser localement chaque portion de l’image de sortie. Ceci permet d’améliorer la généralisation et la robustesse du modèle.
-
Le réseau comprend ensuite un nouvel ensemble de couches de convolution, agrégation...
Exercice pratique : améliorer notre classifieur de chats et chiens
Dans l’exercice proposé à la fin du chapitre Réseaux de neurones à convolution, nous avons créé un réseau, que nous avons entraîné à distinguer des photos de chiens de photos de chats.
Nous allons maintenant utiliser une autre approche, et utiliser un réseau pré-entraîné sur ImageNet, que nous pourrons adapter en le réentraînant sur nos images de chiens et de chats.
Cet exercice pratique est disponible en téléchargement. Il est contenu dans le notebook intitulé « adapter_un_reseau_existant.ipynb ».
Conclusion
Dans ce chapitre, nous avons décrit l’apprentissage par transfert. Nous avons compris comment il permet d’utiliser les connaissances préalables acquises par des modèles pré-entraînés pour résoudre de nouvelles tâches.
Nous avons examiné en détail différentes architectures classiques de réseaux de neurones convolutionnels, en comprenant leurs caractéristiques et leurs avantages respectifs.
Vous disposez maintenant de toutes les informations et de tous les outils pour développer et entraîner des réseaux de neurones à convolution pour la classification : vous savez comment les créer, ou comment en choisir un existant, vous savez aussi les entraîner et mesurer leurs performances.
Dans les chapitres Détection et Segmentation, nous allons aborder différentes tâches de traitement d’images, la détection et la segmentation, qui peuvent être résolues avec des réseaux de neurones très semblables à ceux que nous avons étudiés jusqu’ici.



