
L’apprentissage non supervisé
Introduction
L’apprentissage non supervisé est une méthode de Machine Learning visant à découvrir des motifs, des groupes ou des structures dans des données non étiquetées. Contrairement à l’apprentissage supervisé, où la présence de données étiquetées permet d’évaluer un algorithme au moyen d’un score de performance, l’approche non supervisée est plus subtile et nécessite une analyse approfondie des résultats obtenus. Ces résultats, livrés sans mode d’emploi, peuvent révéler des informations cachées dans les données, telles que des regroupements naturels ou des caractéristiques saillantes.
Dans ce chapitre, nous allons mettre en pratique la réduction dimensionnelle puis le clustering. Nous découvrirons également, pour chacun, comment les évaluer et quels sont les différents algorithmes disponibles.
La réduction dimensionnelle
L’analyse en composantes principales (ACP) est un algorithme fondamental en data science qui permet de réduire la dimensionnalité des données tout en conservant autant que possible leur variance. Cette technique peut être utilisée à deux moments spécifiques d’un projet de data science :
-
À la fin du feature engineering : pour comprendre et visualiser les relations multidimensionnelles entre les variables.
-
Parfois au moment de la modélisation : soit pour lisser les données, soit pour permettre à certains algorithmes de fonctionner plus efficacement lorsque les besoins en mémoire sont trop importants.
Nous allons donc étudier comment le mettre en pratique dans ces deux cas de figure.
1. L’ACP en pratique pour analyser
L’Analyse en Composantes Principales (ACP) est un outil essentiel de l’analyse multidimensionnelle. Elle permet de révéler les relations complexes et cachées entre les variables, tout en identifiant leur influence dans un jeu de données. De plus, l’ACP isole les observations influentes, offrant ainsi une vision plus précise des données.
Ces informations sont accessibles à travers trois graphiques que nous allons apprendre à construire successivement sur le jeu de données du Titanic qui présente des informations variées et soulignera bien les forces de l’ACP.
a. Préparation des données
La préparation des données est nécessaire avant la mise en œuvre d’une ACP. Pour que l’ACP fonctionne correctement, il est nécessaire de :
-
Transformer les variables catégorielles en binaires si certaines ont été sélectionnées. Le recours à des fonctions comme get_dummies de Pandas permet de réaliser ces transformations sur les variables ciblées dans l’option columns.
-
Définir une stratégie pour supprimer les valeurs manquantes : nous imputons par la médiane pour simplifier, bien que 20 % des âges (177) manquent et nécessiteraient une analyse plus approfondie.
-
Standardiser les données : l’utilisation de StandardScaler est recommandée, mais RobustScaler (si présence d’outliers) ou MinMaxScaler (pour...
Le clustering
1. La pratique du clustering avec le K-means
Le K-means est le plus célèbre des algorithmes de clustering. Son but est de regrouper les observations proches en clusters. Il est apprécié pour sa simplicité d’explication et de paramétrage. L’une de ses principales caractéristiques est la possibilité de définir le nombre de clusters souhaités, ce qui n’est pas toujours le cas de ses concurrents.
Cependant, déterminer le nombre optimal de clusters ne va pas de soi et constitue un enjeu. Plusieurs méthodes et tests, comme la méthode du coude (elbow method) ou le coefficient de silhouette, sont disponibles pour nous aider à trouver le partitionnement idéal des données.
Commençons, sans plus tarder, la pratique du clustering sur le jeu des pingouins qui se prête bien à une démonstration sur le clustering.
a. Acquisition et préparation des données
Nous importons le jeu des pingouins et procédons à un rapide nettoyage des données en supprimant les observations présentant des valeurs manquantes :
import seaborn as sns
import pandas as pd
# Chargement des données des pingouins
df = sns.load_dataset("penguins")
# Suppression des lignes avec des valeurs manquantes
df = df.dropna()
display(df.head()) 
Nous construirons notre clustering uniquement sur les variables numériques pour ne pas rendre cet exemple trop complexe mais, dans d’autres cas, l’usage des variables catégorielles est encouragé si cela s’avère nécessaire.
Dans le cas présent, les quatre variables correspondant à la longueur du bec, sa profondeur, la longueur de la nageoire et la masse corporelle semblent suffisantes pour opérer des regroupements. Après nous être préalablement assurés qu’ils avaient tous une distribution anormale, nous produisons une matrice de corrélation de Spearman pour contrôler qu’il n’existe pas de corrélation trop forte :
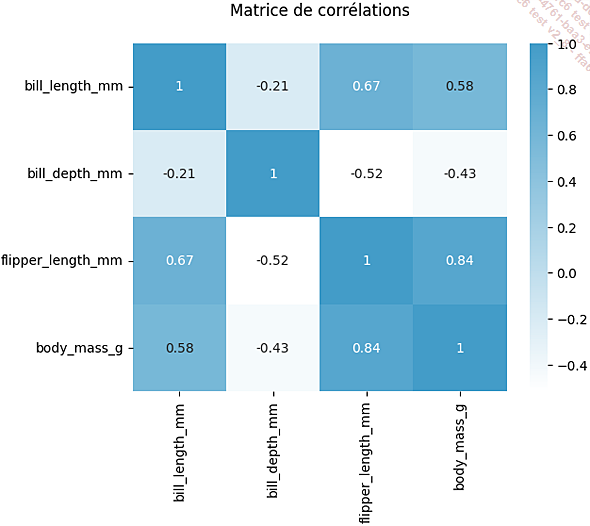
La longueur de la nageoire et la masse corporelle sont fortement corrélées (0,84) mais ne sont pas identiques et ont des natures très différentes. Par conséquent, toutes les variables seront conservées....


