
Être résilient face aux perturbations et attaques
Les incidents
1. L’incident opérationnel
Au-delà des incidents rencontrés par les utilisateurs, il est possible d’identifier des incidents proactivement par les équipes des opérations IT. Dans ce cas, les incidents n’ont pas encore impacté les utilisateurs directement, mais pourraient le faire très rapidement.
Nous l’avons vu précédemment, un incident ne porte pas uniquement lors de l’interruption de service, mais aussi la réduction de qualité de ce même service. Ainsi, lorsque le système de sauvegarde est en échec et si ces mêmes sauvegardes sont garanties, alors il y a bien une réduction de qualité du service et il est nécessaire de le résoudre au plus vite.
2. La priorisation des incidents
La priorisation des incidents est un sous-processus important de la gestion des incidents. La priorisation peut se faire de nombreuses manières, mais en général, deux facteurs sont pris en compte :
-
L’impact : l’impact sur les équipes opérationnelles, qui est fonction du service concerné par l’incident.
-
L’urgence : la durée avant que l’incident ait un impact important sur les équipes opérationnelles.
De manière imagée, on peut faire référence à une bombe pour représenter l’impact et l’urgence, l’impact étant la force d’explosion tandis que l’urgence dépend de la longueur de la mèche.

3. La réponse et la résolution
Le temps de réponse est la durée entre l’ouverture de l’incident et la première réponse tandis que le temps de résolution est la durée entre l’ouverture de l’incident et la confirmation de la résolution de celui-ci.
Les durées ne tiennent compte que des périodes support primaire. Ainsi, même si le support est fourni en 24/7 (soit toutes les heures de tous les jours), seules les périodes de support primaire sont prises en compte dans la durée de résolution.
Pour réduire au maximum la durée de résolution, il est important que les personnes de contact soient documentées au niveau de chacun des services. Cette documentation doit être accessible...
Les problèmes
1. La différence entre problème et incident
À la différence d’un incident, un problème est la cause d’un ou plusieurs incidents. Ainsi, si nous reprenons l’exemple précédent, un disque dur qui se remplit chaque nuit à cause d’une procédure inefficiente avant d’être nettoyé est un problème. Dans certaines situations, cela peut générer des incidents tels que l’indisponibilité d’une application durant une période donnée. La gestion des problèmes fait dès lors l’objet d’un processus dédié.
La gestion des problèmes est proche de la gestion des incidents dans sa conception, ce qui crée d’ailleurs de la confusion pour de nombreuses personnes.
2. La gestion de problème dans sa globalité
Comme nous l’avons vu, la gestion d’un problème est un processus qui est assez complexe tant il y a d’opérations. C’est pour cela que le processus est découpé en différents sous-processus.
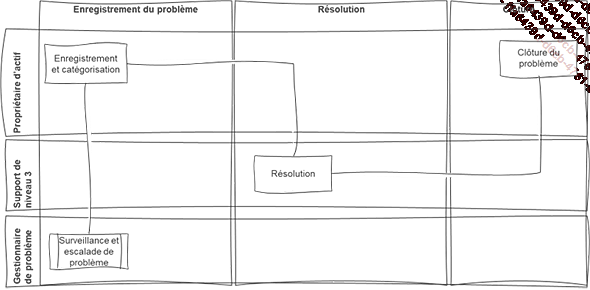
Cette découpe en sous-processus est une bonne pratique autour de la définition et de l’exécution d’un processus.
Par cette découpe, il est ainsi possible d’avoir des responsables différents pour chacun des sous-processus :
|
Processus |
Responsable... |
La reprise d’activité après un sinistre et la continuité métier
1. L’importance des plans de reprise et de continuité
La résilience est critique pour toute organisation et doit gérer le risque omniprésent qu’un sinistre survienne. Un sinistre est un événement indésirable ou une situation problématique qui affecte les systèmes informatiques, les réseaux ou les données d’une organisation. Il peut s’agir d’un incident majeur qui entraîne une interruption du fonctionnement normal des systèmes, d’une perte de données, d’une violation de la sécurité ou n’importe quel autre problème amenant l’organisation dans une situation critique. La résilience permet ainsi de protéger les intérêts des parties prenantes, la réputation de l’organisation et les activités créatrices de valeur. Pour que l’organisation soit résiliente, il est nécessaire d’identifier comment assurer la continuité en amont des évènements. C’est pour cela qu’il est nécessaire de créer un plan de continuité des activités.
La question n’est en effet pas « si » un tel événement va arriver, mais « quand » celui-ci surviendra....
L’ingénierie du chaos
Avec l’ingénierie du chaos, ou encore le chaos engineering en anglais, des perturbations sont volontairement créées pour évaluer la résilience des systèmes d’information. Il s’agit, par exemple, d’interrompre une instance d’un composant de services, et ce, même en production ou encore de provoquer des situations critiques telles qu’elles surviendraient en cas d’attaque informatique. En sachant que le service sera perturbé, les architectes applicatifs et de solutions veilleront à améliorer cette même résilience à travers la disponibilité, la stabilité et même la performance des composants.
De telles perturbations peuvent être automatisées avec des outils spécialisés. Combinés à des systèmes de monitoring et d’observabilité, il est bien souvent possible d’analyser les traces et d’identifier les scénarios menant à des faiblesses, et ainsi les résoudre. Plus l’ingénierie du chaos est utilisée, plus la collaboration entre les équipes augmente, au même rythme que la confiance dans les systèmes et les collaborateurs.
Chaos Monkey est certainement l’outil le plus connu dans ce domaine. Netflix l’a conçu et l’utilise pour désactiver des instances...